HashMap为什么线程不安全
put的不安全
由于多线程对HashMap进行put操作,调用了HashMap的putVal(),具体原因:
假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的;
当线程A执行完第六行由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入;
接着线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入;
最终就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
代码的第38行处有个++size,线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10;
当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU;
接着线程B拿到CPU后从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存;
接着线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存;
此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
扩容不安全
Java7中头插法扩容会导致死循环和数据丢失,Java8中将头插法改为尾插法后死循环和数据丢失已经得到解决,但仍然有数据覆盖的问题。
这是jdk7中存在的问题
transfer过程如下:
对索引数组中的元素遍历
对链表上的每一个节点遍历:用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用头插法插入节点。
循环2,直到链表节点全部转移
循环1,直到所有索引数组全部转移
注意 e.next = newTable[i] 和newTable[i] = e 这两行代码,就会导致链表的顺序翻转。
扩容操作就是新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
concurrentHashMap介绍
concurrentHashMap是一个支持高并发更新与查询的哈希表(基于HashMap)。
hashtable该类不依赖于synchronization去保证线程操作的安全。Collections.synchronizedMap()也可以将map转成线程安全的。而concurrentHashMap在保证安全的前提下,进行get不需要锁定。
底层源码
put方法
回顾hashMap的put方法过程
计算出key的槽位
根据槽位类型进行操作(链表,红黑树)
根据槽位中成员数量进行数据转换,扩容等操作
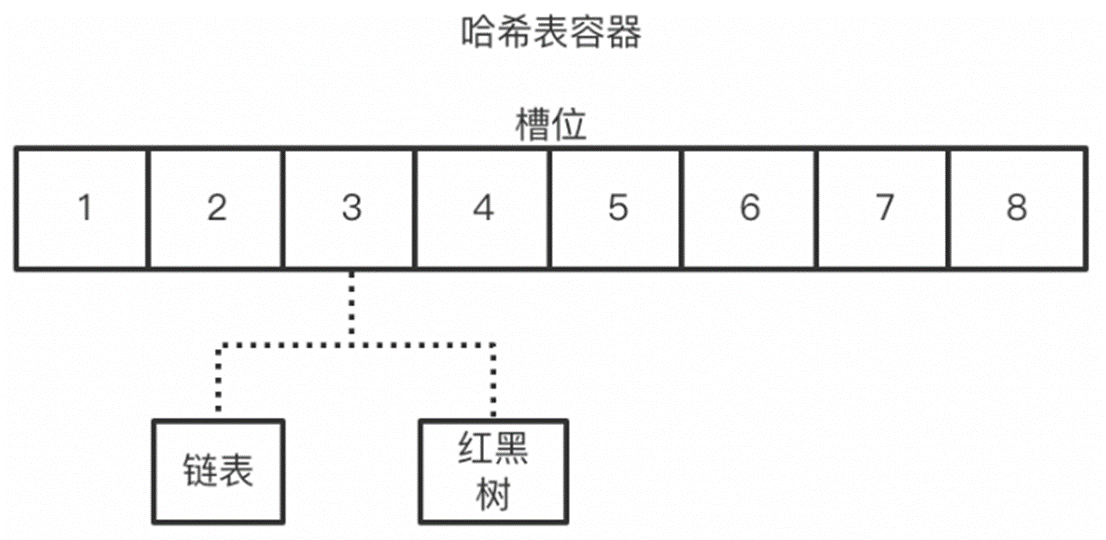 如何高效的执行并发操作:根据上面hashMap的数据结构可以直观的看到,如果以整个容器为一个资源进行锁定,那么就变为了串行操作。而根据hash表的特性,具有冲突的操作只会出现在同一槽位,而与其它槽位的操作互不影响。基于此种判断,那么就可以将资源锁粒度缩小到槽位上,这样热点一分散,冲突的概率就大大降低,并发性能就能得到很好的增强。
如何高效的执行并发操作:根据上面hashMap的数据结构可以直观的看到,如果以整个容器为一个资源进行锁定,那么就变为了串行操作。而根据hash表的特性,具有冲突的操作只会出现在同一槽位,而与其它槽位的操作互不影响。基于此种判断,那么就可以将资源锁粒度缩小到槽位上,这样热点一分散,冲突的概率就大大降低,并发性能就能得到很好的增强。
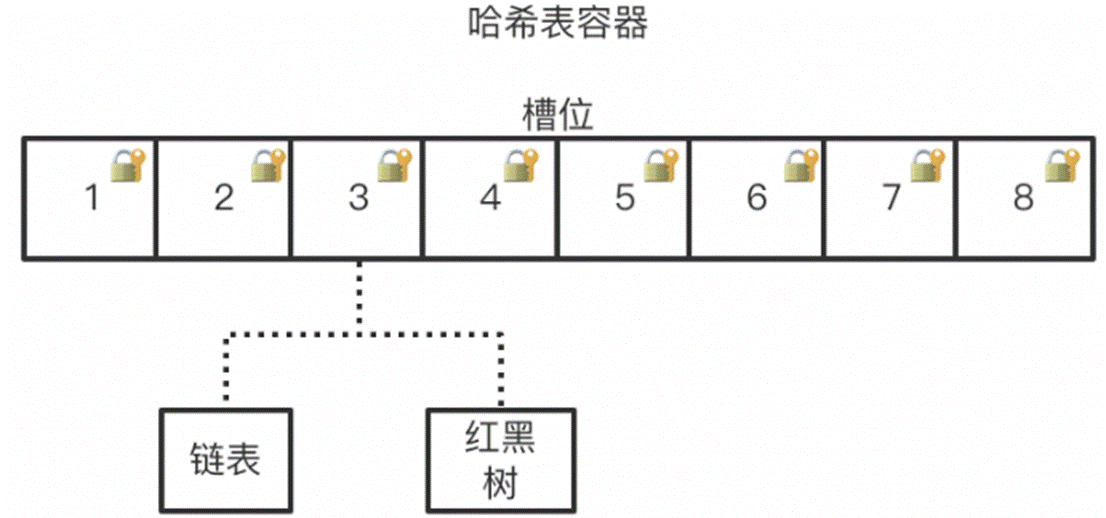 底层源码:
底层源码:
计算hash值的spread方法
初始化 initTable方法
链表转红黑树: treeifyBin
在 put 源码分析也说过,treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。
扩容: tryPresize
如果说 Java8 ConcurrentHashMap 的源码不简单,那么说的就是扩容操作和迁移操作。
这个方法要完完全全看懂还需要看之后的 transfer 方法。
这里的扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍。
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移: transfer
下面这个方法有点长,将原来的 tab 数组的元素迁移到新的 nextTab 数组中。
虽然之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
说到底,transfer 这个方法并没有实现所有的迁移任务,每次调用这个方法只实现了 transferIndex 往前 stride 个位置的迁移工作,其他的需要由外围来控制。
这个时候,再回去仔细看 tryPresize 方法可能就会更加清晰一些了。
get 过程分析
get 方法从来都是最简单的,这里也不例外:
计算 hash 值
根据 hash 值找到数组对应位置: (n - 1) & h
根据该位置处结点性质进行相应查找
如果该位置为 null,那么直接返回 null 就可以了
如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
如果以上 3 条都不满足,那就是链表,进行遍历比对即可
简单说一句,此方法的大部分内容都很简单,只有正好碰到扩容的情况,ForwardingNode.find(int h, Object k) 稍微复杂一些,不过在了解了数据迁移的过程后,这个也就不难了,所以限于篇幅这里也不展开说了。
计算Size
ConcurrentHashMap的size()操作中没有加任何锁,那么它是如何在多线程环境下 线程安全的计算出Map的size的?
查看源码,可以看出size()使用sumCount()方法计算。
ConCurrentHashMap的大小 size 通过 baseCount 和 counterCells 两个变量维护:
在没有并发的情况下,使用一个volatile修饰的 baseCount 变量即可;
当有并发时,CAS 修改 baseCount 失败后,会使用 CounterCell 类,即 创建一个CounterCell对象,设置其volatile修饰的 value 属性为 1,并将其放在ConterCells数组的随机位置;
最终在sumCount()方法中通过累加 baseCount和CounterCells数组里每个CounterCell的值得出Map的总大小Size。
然而 返回的值是一个估计值;如果有并发插入或者删除操作,和实际的数量可能有所不同。
另外size()方法的最大值是 Integer 类型的最大值,而 Map 的 size 有可能超过 Integer.MAX_VALUE,所以JAVA8 建议使用 mappingCount()。
集合线程安全不等于业务安全
需要知道的是,集合线程安全并不等于业务线程安全,并不是说使用了线程安全的集合 如ConcurrentHashMap 就能保证业务的线程安全。这是因为,ConcurrentHashMap只能保证put时是安全的,但是在put操作前如果还有其他的操作,那业务并不一定是线程安全的。
例如存在复合操作,也就是存在多个基本操作(如put、get、remove、containsKey等)组成的操作,例如先判断某个键是否存在containsKey(key),然后根据结果进行插入或更新put(key, value)。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
例如,有两个线程 A 和 B 同时对 ConcurrentHashMap 进行复合操作,如下:
如果线程 A 和 B 的执行顺序是这样:
线程 A 判断 map 中不存在 key
线程 B 判断 map 中不存在 key
线程 B 将 (key, anotherValue) 插入 map
线程 A 将 (key, value) 插入 map
那么最终的结果是 (key, value),而不是预期的 (key, anotherValue)。这就是复合操作的非原子性导致的问题。
那如何保证 ConcurrentHashMap 复合操作的原子性呢?
ConcurrentHashMap 提供了一些原子性的复合操作,如 putIfAbsent、compute、computeIfAbsent 、computeIfPresent、merge等。这些方法都可以接受一个函数作为参数,根据给定的 key 和 value 来计算一个新的 value,并且将其更新到 map 中。
上面的代码可以改写为:
或者:
很多同学可能会说了,这种情况也能加锁同步呀!确实可以,但不建议使用加锁的同步机制,违背了使用 ConcurrentHashMap 的初衷。在使用 ConcurrentHashMap 的时候,尽量使用这些原子性的复合操作方法来保证原子性。
compute()方法
以下是compute()方法的一些典型使用场景:
原子更新键值对:当你需要确保对键值对的更新是原子的,即在一个线程对键值对进行更新时,其他线程无法看到中间状态。
计算键对应的值:如果需要根据键计算新的值来更新映射,
compute()可以确保计算和更新操作的原子性。缓存更新:在缓存实现中,当缓存项需要根据某些条件动态更新时,可以使用
compute()方法来确保更新操作的原子性。并行处理:在并行计算中,当多个线程需要更新同一个
ConcurrentHashMap中的项时,compute()可以用来确保每个键的处理是互不干扰的。
使用示例:
对比总结
HashTable: 使用了synchronized关键字对put等操作进行加锁;
ConcurrentHashMap JDK1.7: 使用分段锁机制实现;
ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和CAS原子操作实现;synchronized锁住桶,以及大量的CAS操作
扩展:JDK7的分段锁机制
在 JDK7 中 ConcurrentHashMap 底层数据结构是数组加链表,源码如下:
其中并发级别控制了Segment的个数,在一个ConcurrentHashMap创建后Segment的个数是不能变的,扩容过程过改变的是每个Segment的大小。
段Segment继承了重入锁ReentrantLock,有了锁的功能,每个锁控制的是一段,如下图所示:
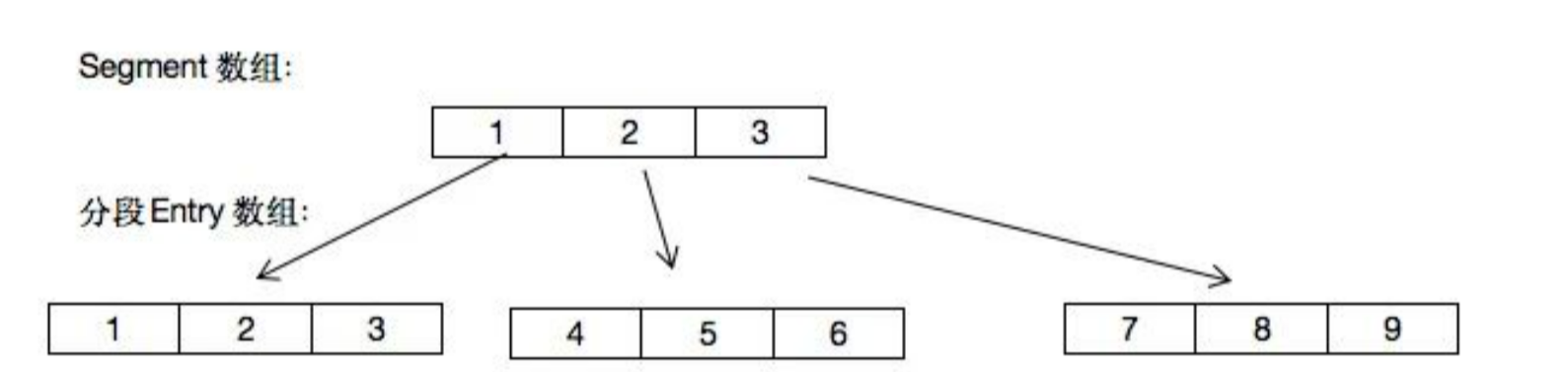 将一个大的Map分成若干个小的segment,每个segment使用一个独立的锁来保证线程安全,多个线程访问不同segment时可以并发访问,从而提高了并发性能。这相对于直接对整个map同步synchronized是有优势的。
将一个大的Map分成若干个小的segment,每个segment使用一个独立的锁来保证线程安全,多个线程访问不同segment时可以并发访问,从而提高了并发性能。这相对于直接对整个map同步synchronized是有优势的。
那为什么J DK8 又舍弃掉了分段锁呢?
Segment的个数是不能变的,因此随着put的数据越多,每个Segment也就越来越大,锁的粒度也就会变得越大。此时,当某个段很大时,分段锁的性能会下降。
分成很多段时会比较浪费内存空间(不连续,碎片化);
操作map时竞争同一个分段锁的概率非常小时,分段锁反而会造成更新等操作的长时间等待;
因此,Java8中废除了分段锁,采用了一种新的方式来保证线程安全性。
扩展:为什么JDK8不用ReentrantLock而用synchronized
减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
为什么key 和 value 不允许为 null
HashMap中,null可以作为键或者值都可以。而在ConcurrentHashMap中,key和value都不允许为null。
ConcurrentHashMap的作者——Doug Lea的解释如下:
 主要意思就是说:
主要意思就是说:
ConcurrentMap(如ConcurrentHashMap、ConcurrentSkipListMap)不允许使用null值的主要原因是,在非并发的Map中(如HashMap),是可以容忍模糊性(二义性)的,而在并发Map中是无法容忍的。
假如说,所有的Map都支持null的话,那么map.get(key)就可以返回null,但是,这时候就会存在一个不确定性,当你拿到null的时候,你是不知道他是因为本来就存了一个null进去还是说就是因为没找到而返回了null。
在HashMap中,因为它的设计就是给单线程用的,所以当我们map.get(key)返回null的时候,我们是可以通过map.contains(key)检查来进行检测的,如果它返回true,则认为是存了一个null,否则就是因为没找到而返回了null。
但是,像ConcurrentHashMap,它是为并发而生的,它是要用在并发场景中的,当我们map.get(key)返回null的时候,是没办法通过map.contains(key)(ConcurrentHashMap有这个方法,但不可靠)检查来准确的检测,因为在检测过程中可能会被其他线程锁修改,而导致检测结果并不可靠。
所以,为了让ConcurrentHashMap的语义更加准确,不存在二义性的问题,他就不支持null。