前言
线程池ThreadPoolExecutor,可以通过对任务队列和线程的有效管理实现了对并发任务的处理。
然而,ThreadPoolExecutor有两个明显的缺点:
无法对大任务进行拆分,对于某个任务只能由单线程执行;
获取任务时主要调用的是workQueue.poll()方法或take(), 这两个方法都会阻塞式的从队列中获取元素。也就是说,工作线程从队列中获取任务时存在竞争情况
这两个缺点都会影响任务的执行效率,要知道高并发场景中的每一毫秒都弥足珍贵。
分治算法与Fork/Join
在并发计算中,Fork/Join模式往往用于对大任务的并行计算,它通过递归的方式对任务不断地拆解,再将结果进行合并。如果从其思想上看,Fork/Join并不复杂,其本质是分治算法(Divide-and-Conquer) 的应用。
分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。分治算法的步骤如下:
分解:将要解决的问题划分成若干规模较小的同类问题;
求解:当子问题划分得足够小时,用较简单的方法解决;
合并:按原问题的要求,将子问题的解逐层合并构成原问题的解。
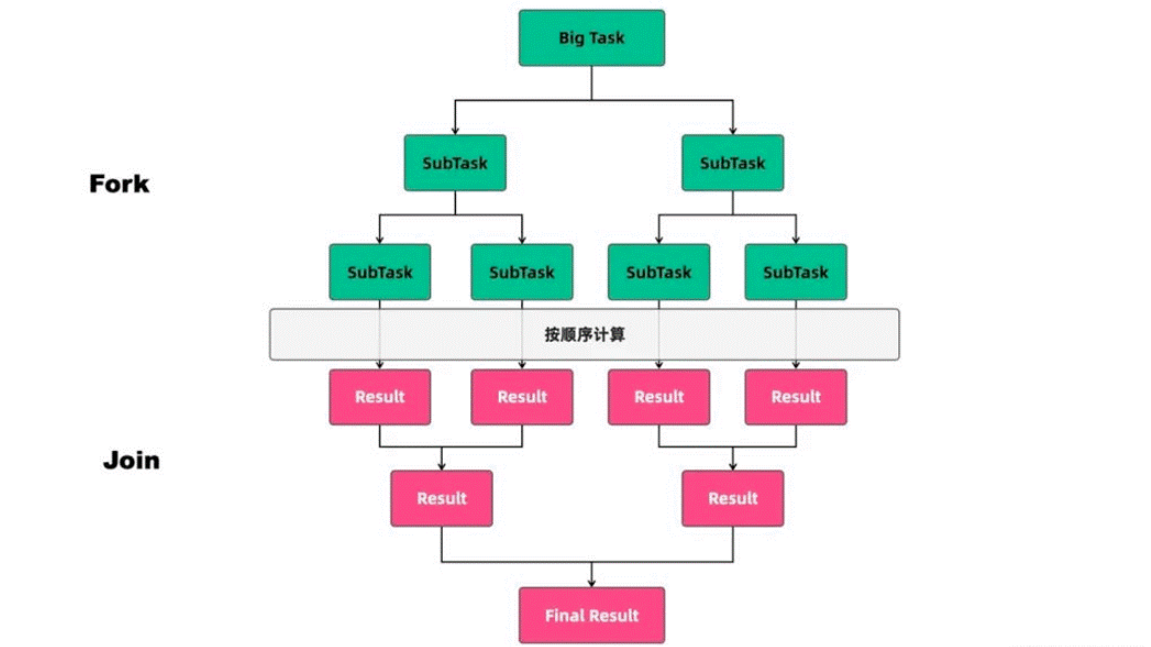 Fork/Join对任务的拆分和对结果合并过程也是如此,可以用下面伪代码来表示:
Fork/Join对任务的拆分和对结果合并过程也是如此,可以用下面伪代码来表示:
所以,理解Fork/Join模型和ForkJoinPool线程池,首先要理解其背后的算法的目的和思想。
其实,在 Java 8 中引入的并行流计算,内部就是采用的 ForkJoinPool 来实现的。
应用场景
场景:给定两个自然数,计算两个两个数之间的总和。比如1~n之间的和:1+2+3+…+n
为了解决这个问题,创建了TheKingRecursiveSumTask这个核心类,它继承于RecursiveTask. RecursiveTask是ForkJoinPool中的一种任务类型,TheKingRecursiveSumTask中定义了任务计算的起止范围(sumBegin和sumEnd)和拆分阈值(threshold),以及核心计算逻辑compute().
在下面的代码中,设置的计算区间值0~10000000,当计算的个数超过100时,将对任务进行拆分,最大并发数设置为16.
运行结果如下:
从计算结果中可以看到,ForkJoinPool总共进行了131071次的任务拆分,最终的计算结果是49999995000000,耗时207毫秒。不过,细心的你可能已经发现了,ForkJoin的并行计算的耗时竟然比单程程还慢?并且足足慢了近5倍!这种情况可能由以下几个原因造成:
任务分解和管理开销: ForkJoin框架通过将大任务分解为许多小任务并行执行来提高效率。每个小任务都需要额外的时间来管理和调度。如果这些任务非常小,那么管理任务的开销可能会超过并行处理所带来的性能提升,尤其是当任务分解得过于细致时。因此需要合理选择任务的尺寸,避免任务过小导致调度开销过大。
线程创建与上下文切换开销: 尽管ForkJoin框架利用工作窃取算法(work-stealing algorithm)来减少线程间的竞争,但在高并发情况下,线程初始化和上下文切换仍然会造成显著的性能开销。
内存访问冲突: 并行程序经常需要访问共享资源或内存,这可能导致多个线程之间发生竞争,从而降低效率。特别是在多核处理器上,不同线程可能会竞争同一缓存行(cache line),导致性能下降。
负载不均衡: 如果任务之间的工作量差异较大,ForkJoin框架虽然能通过工作窃取算法尝试均衡负载,但如果初始分配的不均或窃取策略不够高效,也可能导致某些线程比其他线程忙碌得多,从而造成资源的浪费和效率低下。
适用性问题: 并不是所有任务都适合并行处理。对于计算密集型少量任务或者由多个依赖步骤组成的任务,单线程执行可能更为高效。因此需要评估任务是否适合并行处理,以及任务之间的依赖关系,避免不必要的并行。
Fork/Join框架简介
Fork/Join框架是Java并发工具包中的一种可以将一个大任务拆分为很多小任务来异步执行的工具,自JDK1.7引入。
三个模块及关系
Fork/Join框架主要包含三个模块:
任务对象: ForkJoinTask(包括RecursiveTask、RecursiveAction、CountedCompleter)
执行Fork/Join任务的线程: ForkJoinWorkerThread
线程池: ForkJoinPool
这三者的关系是: ForkJoinPool可以通过池中的ForkJoinWorkerThread来处理ForkJoinTask任务。
ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务),RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask,RecursiveAction 是一个无返回值的 RecursiveTask,CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
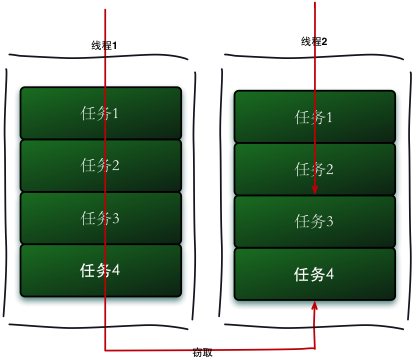
work-stealing(工作窃取)算法
work-stealing(工作窃取)算法: 线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
说白了就是,当有线程把当前的任务队列都处理完了之后,它还可以到其它还没处理完任务的队列的尾部窃取任务进行处理。
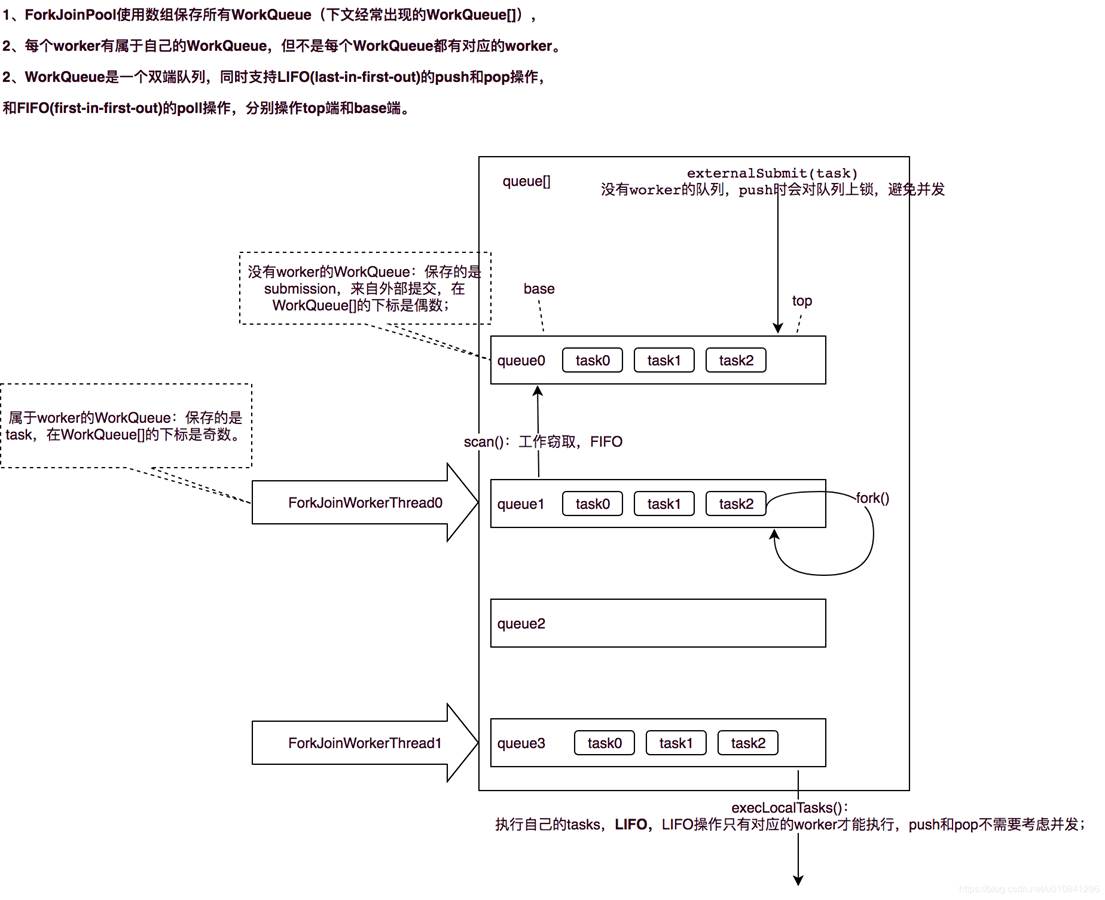
 在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列。
队列支持三个功能push、pop、poll
push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
划分的子任务调用fork时,都会被push到自己的队列中。
默认情况下,工作线程从自己的双端队列获取出任务并执行。
当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务。
 工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。某些情况下也会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。某些情况下也会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
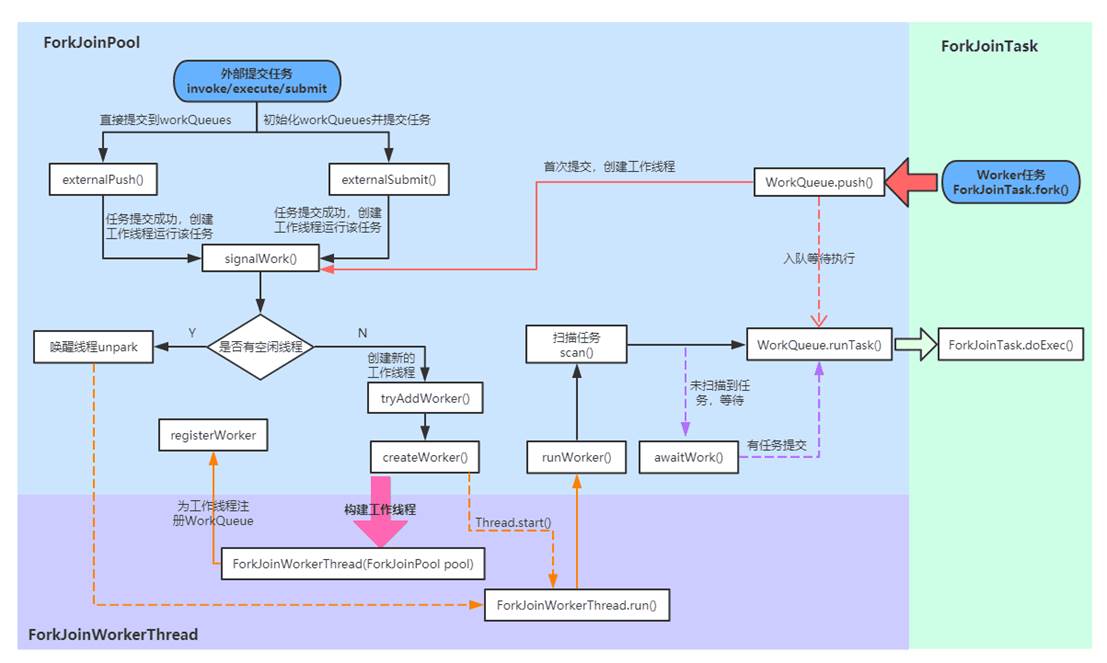
Fork/Join 框架的执行流程
上图可以看出ForkJoinPool 中的任务执行分两种:
直接通过 FJP 提交的外部任务(external/submissions task),存放在 workQueues 的偶数槽位;
通过内部 fork 分割的子任务(Worker task),存放在 workQueues 的奇数槽位。
那Fork/Join 框架的执行流程是什么样的?
Fork/Join类关系
ForkJoinPool继承关系
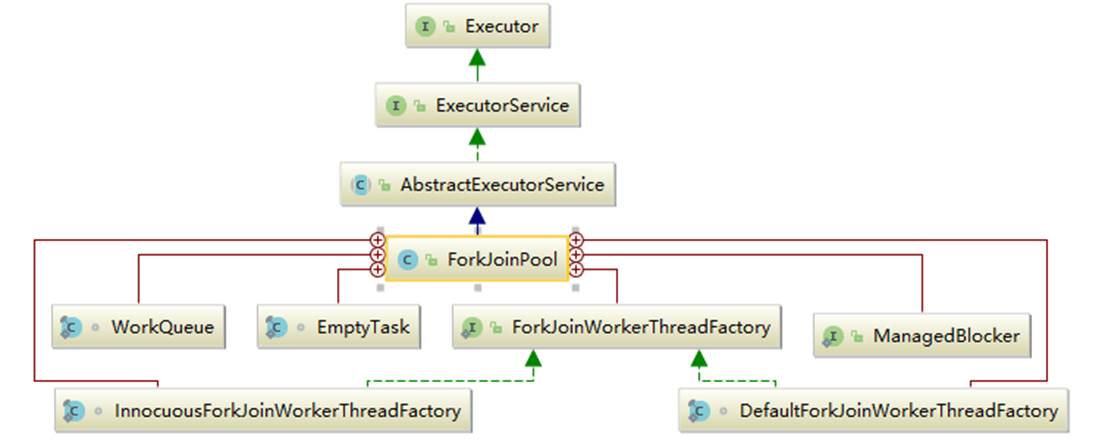 内部类介绍:
内部类介绍:
ForkJoinWorkerThreadFactory: 内部线程工厂接口,用于创建工作线程ForkJoinWorkerThread
DefaultForkJoinWorkerThreadFactory: ForkJoinWorkerThreadFactory 的默认实现类
InnocuousForkJoinWorkerThreadFactory: 实现了 ForkJoinWorkerThreadFactory,无许可线程工厂,当系统变量中有系统安全管理相关属性时,默认使用这个工厂创建工作线程。
EmptyTask: 内部占位类,用于替换队列中 join 的任务。
ManagedBlocker: 为 ForkJoinPool 中的任务提供扩展管理并行数的接口,一般用在可能会阻塞的任务(如在 Phaser 中用于等待 phase 到下一个generation)。
WorkQueue: ForkJoinPool 的核心数据结构,本质上是work-stealing 模式的双端任务队列,内部存放 ForkJoinTask 对象任务,使用 @Contented 注解修饰防止伪共享。
工作线程在运行中产生新的任务(通常是因为调用了 fork())时,此时可以把 WorkQueue 的数据结构视为一个栈,新的任务会放入栈顶(top 位);工作线程在处理自己工作队列的任务时,按照 LIFO 的顺序。
工作线程在处理自己的工作队列同时,会尝试窃取一个任务(可能是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的队列任务),此时可以把 WorkQueue 的数据结构视为一个 FIFO 的队列,窃取的任务位于其他线程的工作队列的队首(base位)。
伪共享状态: 缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
ForkJoinTask继承关系
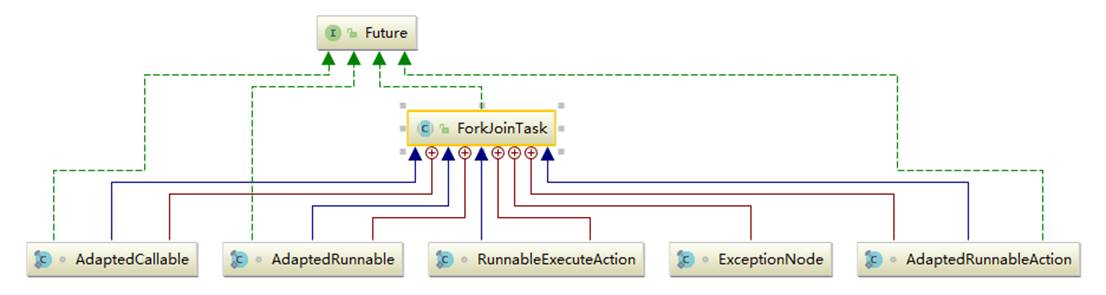 ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务,实际上ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。 其内部类都比较简单,ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务(因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务,实际上ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。 其内部类都比较简单,ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务(因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
Fork/Join框架源码解析
如果让我们来设计一个 Fork/Join 框架,该如何设计?
第一步分割任务。首先需要有一个 fork 类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
第二步执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join 使用两个类来完成以上两件事情:
ForkJoinTask:我们要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务中执行 fork() 和 join() 操作的机制,通常情况下我们不需要直接继承 ForkJoinTask 类,而只需要继承它的子类,Fork/Join 框架提供了以下两个子类:
RecursiveAction:用于没有返回结果的任务。
RecursiveTask :用于有返回结果的任务。
ForkJoinPool :ForkJoinTask 需要通过 ForkJoinPool 来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
分析思路: 在对类层次结构有了解以后,先看下内部核心参数,然后分析上述流程图。会分4个部分:
首先介绍任务的提交流程 - 外部任务(external/submissions task)提交
然后介绍任务的提交流程 - 子任务(Worker task)提交
再分析任务的执行过程(ForkJoinWorkerThread.run()到ForkJoinTask.doExec()这一部分);
最后介绍任务的结果获取(ForkJoinTask.join()和ForkJoinTask.invoke())
ForkJoinPool
核心参数
在后面的源码解析中,我们会看到大量的位运算,这些位运算都是通过我们接下来介绍的一些常量参数来计算的。
例如,如果要更新活跃线程数,使用公式(UC_MASK & (c + AC_UNIT)) | (SP_MASK & c);c 代表当前 ctl,UC_MASK 和 SP_MASK 分别是高位和低位掩码,AC_UNIT 为活跃线程的增量数,使用(UC_MASK & (c + AC_UNIT))就可以计算出高32位,然后再加上低32位(SP_MASK & c),就拼接成了一个新的ctl。
这些运算的可读性很差,看起来有些复杂。在后面源码解析中有位运算的地方我都会加上注释,大家只需要了解它们的作用即可。
ForkJoinPool 与 内部类 WorkQueue 共享的一些常量:
ForkJoinPool 中的相关常量和实例字段:
说明: ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成:
AC: 正在运行工作线程数减去目标并行度,高16位
TC: 总工作线程数减去目标并行度,中高16位
SS: 栈顶等待线程的版本计数和状态,中低16位
ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
在后面的源码解析中,某些地方也提取了ctl的低32位(sp=(int)ctl)来检查工作线程状态,例如,当sp不为0时说明当前还有空闲工作线程。
ForkJoinPool.WorkQueue 中的相关属性:
ForkJoinTask
核心参数
Fork/Join框架源码解析
构造函数
说明: 在 ForkJoinPool 中我们可以自定义四个参数:
parallelism: 并行度,默认为CPU数,最小为1
factory: 工作线程工厂;
handler: 处理工作线程运行任务时的异常情况类,默认为null;
asyncMode: 是否为异步模式,默认为 false。如果为true,表示子任务的执行遵循 FIFO 顺序并且任务不能被合并(join),这种模式适用于工作线程只运行事件类型的异步任务。
在多数场景使用时,如果没有太强的业务需求,我们一般直接使用 ForkJoinPool 中的common池,在JDK1.8之后提供了ForkJoinPool.commonPool()方法可以直接使用common池,来看一下它的构造:
使用common pool的优点就是我们可以通过指定系统参数的方式定义“并行度、线程工厂和异常处理类”;并且它使用的是同步模式,也就是说可以支持任务合并(join)。
执行流程 - 外部任务(external/submissions task)提交
向 ForkJoinPool 提交任务有三种方式:
invoke()会等待任务计算完毕并返回计算结果;
execute()是直接向池提交一个任务来异步执行,无返回结果;
submit()也是异步执行,但是会返回提交的任务,在适当的时候可通过task.get()获取执行结果。
这三种提交方式都都是调用externalPush()方法来完成,所以接下来我们将从externalPush()方法开始逐步分析外部任务的执行过程。
externalPush(ForkJoinTask<?> task)
首先说明一下externalPush和externalSubmit两个方法的联系: 它们的作用都是把任务放到队列中等待执行。不同的是,externalSubmit可以说是完整版的externalPush,在任务首次提交时,需要初始化workQueues及其他相关属性,这个初始化操作就是externalSubmit来完成的;而后再向池中提交的任务都是通过简化版的externalSubmit-externalPush来完成。
externalPush的执行流程很简单: 首先找到一个随机偶数槽位的 workQueue,然后把任务放入这个 workQueue 的任务数组中,并更新top位。如果队列的剩余任务数小于1,则尝试创建或激活一个工作线程来运行任务(防止在externalSubmit初始化时发生异常导致工作线程创建失败)。
externalSubmit(ForkJoinTask<?> task)
说明: externalSubmit是externalPush的完整版本,主要用于第一次提交任务时初始化workQueues及相关属性,并且提交给定任务到队列中。具体执行步骤如下:
如果池为终止状态(runState<0),调用tryTerminate来终止线程池,并抛出任务拒绝异常;
如果尚未初始化,就为 FJP 执行初始化操作: 初始化stealCounter、创建workerQueues,然后继续自旋;
初始化完成后,执行在externalPush中相同的操作: 获取 workQueue,放入指定任务。任务提交成功后调用signalWork方法创建或激活线程;
如果在步骤3中获取到的 workQueue 为null,会在这一步中创建一个 workQueue,创建成功继续自旋执行第三步操作;
如果非上述情况,或者有线程争用资源导致获取锁失败,就重新获取线程探针值继续自旋。
signalWork(WorkQueue[] ws, WorkQueue q)
说明: 新建或唤醒一个工作线程,在externalPush、externalSubmit、workQueue.push、scan中调用。如果还有空闲线程,则尝试唤醒索引到的 WorkQueue 的parker线程;如果工作线程过少((ctl & ADD_WORKER) != 0L),则调用tryAddWorker添加一个新的工作线程。
tryAddWorker(long c)
说明: 尝试添加一个新的工作线程,首先更新ctl中的工作线程数,然后调用createWorker()创建工作线程。
createWorker()
说明: createWorker首先通过线程工厂创一个新的ForkJoinWorkerThread,然后启动这个工作线程(wt.start())。如果期间发生异常,调用deregisterWorker处理线程创建失败的逻辑(deregisterWorker在后面再详细说明)。
ForkJoinWorkerThread 的构造函数如下:
可以看到 ForkJoinWorkerThread 在构造时首先调用父类 Thread 的方法,然后为工作线程注册pool和workQueue,而workQueue的注册任务由ForkJoinPool.registerWorker来完成。
registerWorker()
说明: registerWorker是 ForkJoinWorkerThread 构造器的回调函数,用于创建和记录工作线程的 WorkQueue。比较简单,就不多赘述了。注意在此为工作线程创建的 WorkQueue 是放在奇数索引的(代码行: i = ((s << 1) | 1) & m;)
小结
在createWorker()中启动工作线程后(wt.start()),当为线程分配到CPU执行时间片之后会运行 ForkJoinWorkerThread 的run方法开启线程来执行任务。工作线程执行任务的流程我们在讲完内部任务提交之后会统一讲解。
执行流程: 子任务(Worker task)提交
子任务的提交相对比较简单,由任务的fork()方法完成。通过上面的流程图可以看到任务被分割(fork)之后调用了ForkJoinPool.WorkQueue.push()方法直接把任务放到队列中等待被执行。
ForkJoinTask.fork()
说明: 如果当前线程是 Worker 线程,说明当前任务是fork分割的子任务,通过ForkJoinPool.workQueue.push()方法直接把任务放到自己的等待队列中;否则调用ForkJoinPool.externalPush()提交到一个随机的等待队列中(外部任务)。
ForkJoinPool.WorkQueue.push()
说明: 首先把任务放入等待队列并更新top位;如果当前 WorkQueue 为新建的等待队列(top-base<=1),则调用signalWork方法为当前 WorkQueue 新建或唤醒一个工作线程;如果 WorkQueue 中的任务数组容量过小,则调用growArray()方法对其进行两倍扩容,growArray()方法源码如下:
小结
到此,两种任务的提交流程都已经解析完毕,下一节我们来一起看看任务提交之后是如何被运行的。
执行流程: 任务执行
回到我们开始时的流程图,在ForkJoinPool .createWorker()方法中创建工作线程后,会启动工作线程,系统为工作线程分配到CPU执行时间片之后会执行 ForkJoinWorkerThread 的run()方法正式开始执行任务。
ForkJoinWorkerThread.run()
说明: 方法很简单,在工作线程运行前后会调用自定义钩子函数(onStart和onTermination),任务的运行则是调用了ForkJoinPool.runWorker()。如果全部任务执行完毕或者期间遭遇异常,则通过ForkJoinPool.deregisterWorker关闭工作线程并处理异常信息(deregisterWorker方法我们后面会详细讲解)。
ForkJoinPool.runWorker(WorkQueue w)
说明: runWorker是 ForkJoinWorkerThread 的主运行方法,用来依次执行当前工作线程中的任务。函数流程很简单: 调用scan方法依次获取任务,然后调用WorkQueue .runTask运行任务;如果未扫描到任务,则调用awaitWork等待,直到工作线程/线程池终止或等待超时。
ForkJoinPool.scan(WorkQueue w, int r)
说明: 扫描并尝试偷取一个任务。使用w.hint进行随机索引 WorkQueue,也就是说并不一定会执行当前 WorkQueue 中的任务,而是偷取别的Worker的任务来执行。
函数的大概执行流程如下:
取随机位置的一个 WorkQueue;
获取base位的 ForkJoinTask,成功取到后更新base位并返回任务;如果取到的 WorkQueue 中任务数大于1,则调用signalWork创建或唤醒其他工作线程;
如果当前工作线程处于不活跃状态(INACTIVE),则调用tryRelease尝试唤醒栈顶工作线程来执行。
tryRelease源码如下:
如果base位任务为空或发生偏移,则对索引位进行随机移位,然后重新扫描;
如果扫描整个workQueues之后没有获取到任务,则设置当前工作线程为INACTIVE状态;然后重置checkSum,再次扫描一圈之后如果还没有任务则跳出循环返回null。
ForkJoinPool.awaitWork(WorkQueue w, int r)
说明: 回到runWorker方法,如果scan方法未扫描到任务,会调用awaitWork等待获取任务。函数的具体执行流程大家看源码,这里简单说一下:
- 在等待获取任务期间,如果工作线程或线程池已经终止则直接返回false。如果当前无 active 线程,尝试终止线程池并返回false,如果终止失败并且当前是最后一个等待的 Worker,就阻塞指定的时间(IDLE_TIMEOUT);等到届期或被唤醒后如果发现自己是scanning(scanState >= 0)状态,说明已经等到任务,跳出等待返回true继续 scan,否则的更新ctl并返回false。
WorkQueue.runTask()
说明: 在scan方法扫描到任务之后,调用WorkQueue.runTask()来执行获取到的任务,大概流程如下:
标记scanState为正在执行状态;
更新currentSteal为当前获取到的任务并执行它,任务的执行调用了ForkJoinTask.doExec()方法,源码如下:
调用execLocalTasks依次执行当前WorkerQueue中的任务,源码如下:
更新偷取任务数;
还原scanState并执行钩子函数。
ForkJoinPool.deregisterWorker(ForkJoinWorkerThread wt, Throwable ex)
说明: deregisterWorker方法用于工作线程运行完毕之后终止线程或处理工作线程异常,主要就是清除已关闭的工作线程或回滚创建线程之前的操作,并把传入的异常抛给 ForkJoinTask 来处理。具体步骤见源码注释。
小结
本节我们对任务的执行流程进行了说明,后面我们将继续介绍任务的结果获取(join/invoke)。
获取任务结果 - ForkJoinTask.join() / ForkJoinTask.invoke()
join() :
invoke() :
说明: join()方法一把是在任务fork()之后调用,用来获取(或者叫“合并”)任务的执行结果。
ForkJoinTask的join()和invoke()方法都可以用来获取任务的执行结果(另外还有get方法也是调用了doJoin来获取任务结果,但是会响应运行时异常),它们对外部提交任务的执行方式一致,都是通过externalAwaitDone方法等待执行结果。不同的是invoke()方法会直接执行当前任务;而join()方法则是在当前任务在队列 top 位时(通过tryUnpush方法判断)才能执行,如果当前任务不在 top 位或者任务执行失败调用ForkJoinPool.awaitJoin方法帮助执行或阻塞当前 join 任务。(所以在官方文档中建议了我们对ForkJoinTask任务的调用顺序,一对 fork-join操作一般按照如下顺序调用: a.fork(); b.fork(); b.join(); a.join();。因为任务 b 是后面进入队列,也就是说它是在栈顶的(top 位),在它fork()之后直接调用join()就可以直接执行而不会调用ForkJoinPool.awaitJoin方法去等待。)
在这些方法中,join()相对比较全面,所以之后的讲解我们将从join()开始逐步向下分析,首先看一下join()的执行流程:
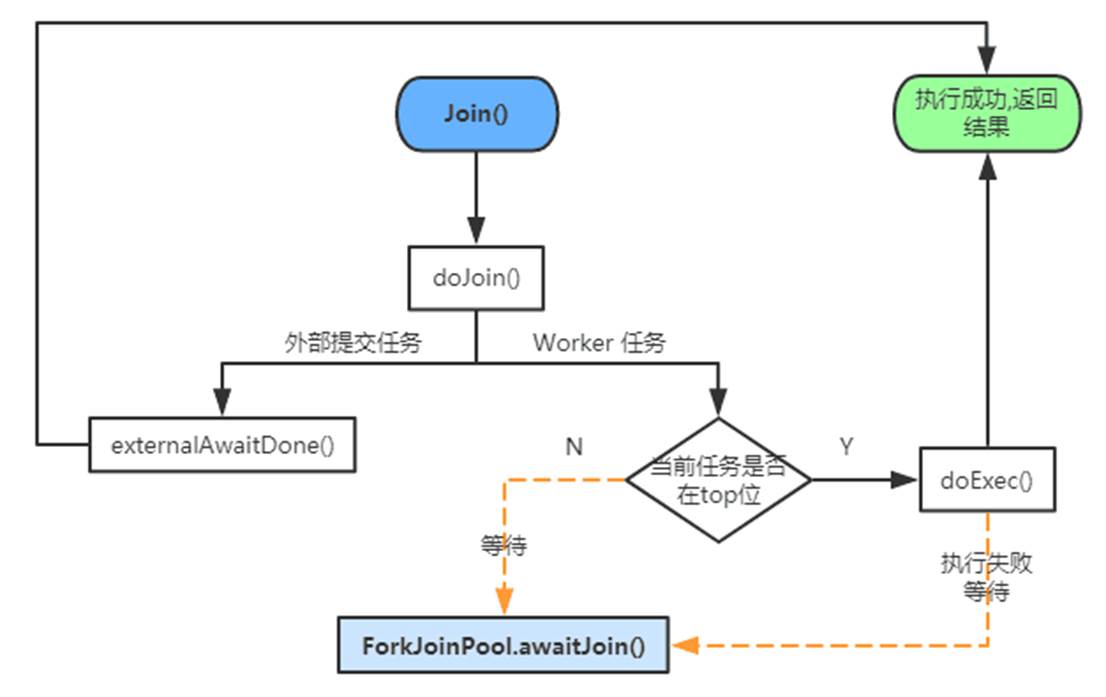 后面的源码分析中,我们首先讲解比较简单的外部 join 任务(externalAwaitDone),然后再讲解内部 join 任务(从ForkJoinPool.awaitJoin()开始)。
后面的源码分析中,我们首先讲解比较简单的外部 join 任务(externalAwaitDone),然后再讲解内部 join 任务(从ForkJoinPool.awaitJoin()开始)。
ForkJoinTask.externalAwaitDone()
说明: 如果当前join为外部调用,则调用此方法执行任务,如果任务执行失败就进入等待。方法本身是很简单的,需要注意的是对不同的任务类型分两种情况:
如果我们的任务为 CountedCompleter 类型的任务,则调用externalHelpComplete方法来执行任务。
其他类型的 ForkJoinTask 任务调用tryExternalUnpush来执行,源码如下:
tryExternalUnpush的作用就是判断当前任务是否在top位,如果是则弹出任务,然后在externalAwaitDone中调用doExec()执行任务。
ForkJoinPool.awaitJoin()
说明: 如果当前 join 任务不在Worker等待队列的top位,或者任务执行失败,调用此方法来帮助执行或阻塞当前 join 的任务。函数执行流程如下:
由于每次调用awaitJoin都会优先执行当前join的任务,所以首先会更新currentJoin为当前join任务;
进入自旋:
首先检查任务是否已经完成(通过task.status < 0判断),如果给定任务执行完毕|取消|异常 则跳出循环返回执行状态s;
如果是 CountedCompleter 任务类型,调用helpComplete方法来完成join操作(后面笔者会开新篇来专门讲解CountedCompleter,本篇暂时不做详细解析);
非 CountedCompleter 任务类型调用WorkQueue.tryRemoveAndExec尝试执行任务;
如果给定 WorkQueue 的等待队列为空或任务执行失败,说明任务可能被偷,调用helpStealer帮助偷取者执行任务(也就是说,偷取者帮我执行任务,我去帮偷取者执行它的任务);
再次判断任务是否执行完毕(task.status < 0),如果任务执行失败,计算一个等待时间准备进行补偿操作;
调用tryCompensate方法为给定 WorkQueue 尝试执行补偿操作。在执行补偿期间,如果发现 资源争用|池处于unstable状态|当前Worker已终止,则调用ForkJoinTask.internalWait()方法等待指定的时间,任务唤醒之后继续自旋,ForkJoinTask.internalWait()源码如下:
在awaitJoin中,我们总共调用了三个比较复杂的方法: tryRemoveAndExec、helpStealer和tryCompensate,下面我们依次讲解。
WorkQueue.tryRemoveAndExec(ForkJoinTask<?> task)
说明: 从top位开始自旋向下找到给定任务,如果找到把它从当前 Worker 的任务队列中移除并执行它。注意返回的参数: 如果任务队列为空或者任务未执行完毕返回true;任务执行完毕返回false。
ForkJoinPool.helpStealer(WorkQueue w, ForkJoinTask<?> task)
说明: 如果队列为空或任务执行失败,说明任务可能被偷,调用此方法来帮助偷取者执行任务。基本思想是: 偷取者帮助我执行任务,我去帮助偷取者执行它的任务。 函数执行流程如下:
循环定位偷取者,由于Worker是在奇数索引位,所以每次会跳两个索引位。定位到偷取者之后,更新调用者 WorkQueue 的hint为偷取者的索引,方便下次定位; 定位到偷取者后,开始帮助偷取者执行任务。从偷取者的base索引开始,每次偷取一个任务执行。在帮助偷取者执行任务后,如果调用者发现本身已经有任务(w.top != top),则依次弹出自己的任务(LIFO顺序)并执行(也就是说自己偷自己的任务执行)。
ForkJoinPool.tryCompensate(WorkQueue w)
说明: 具体的执行看源码及注释,这里我们简单总结一下需要和不需要补偿的几种情况:
需要补偿 :
调用者队列不为空,并且有空闲工作线程,这种情况会唤醒空闲线程(调用tryRelease方法)
池尚未停止,活跃线程数不足,这时会新建一个工作线程(调用createWorker方法)
不需要补偿 :
调用者已终止或池处于不稳定状态
总线程数大于并行度 && 活动线程数大于1 && 调用者任务队列为空
Fork/Join的陷阱与注意事项
使用Fork/Join框架时,需要注意一些陷阱, 在下面 斐波那契数列例子中你将看到示例:
避免不必要的fork()
划分成两个子任务后,不要同时调用两个子任务的fork()方法。
表面上看上去两个子任务都fork(),然后join()两次似乎更自然。但事实证明,直接调用compute()效率更高。因为直接调用子任务的compute()方法实际上就是在当前的工作线程进行了计算(线程重用),这比“将子任务提交到工作队列,线程又从工作队列中拿任务”快得多。
当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的invokeAll方法,因为使用它们能避免不必要的fork()。
注意fork()、compute()、join()的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意。
如果我们写成:
或者
这两种实际上都没有并行。
选择合适的子任务粒度
选择划分子任务的粒度(顺序执行的阈值)很重要,因为使用Fork/Join框架并不一定比顺序执行任务的效率高: 如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork()子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗。
官方文档给出的粗略经验是: 任务应该执行100~10000个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是“上上策”。
和其他Java代码一样,Fork/Join框架测试时需要“预热”或者说执行几遍才会被JIT(Just-in-time)编译器优化,所以测试性能之前跑几遍程序很重要。
避免重量级任务划分与结果合并
Fork/Join的很多使用场景都用到数组或者List等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免System.arraycopy这样耗时耗空间的操作,从而最小化任务的处理开销