为什么需要SPI机制
SPI和API的区别是什么
SPI是一种跟API相对应的反向设计思想:API由实现方确定标准规范和功能,调用方无权做任何干预; 而SPI是由调用方确定标准规范,也就是接口,然后调用方依赖此接口,第三方实现此接口,这样做就可以方便的进行扩展,类似于插件机制,这是SPI出现的需求背景。
SPI : “接口”位于“调用方”所在的“包”中
概念上更依赖调用方。
组织上位于调用方所在的包中。
实现位于独立的包中。
常见的例子是:插件模式的插件。
API : “接口”位于“实现方”所在的“包”中
概念上更接近实现方。
组织上位于实现方所在的包中。
实现和接口在一个包中。
什么是SPI机制
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,例如数据库中的java.sql.Driver接口,不同的厂商可以针对同一接口做出不同的实现,如下图所示,MySQL和PostgreSQL都有不同的实现提供给用户。 而Java的SPI机制可以为某个接口寻找服务实现,Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。
SPI整体机制图如下:
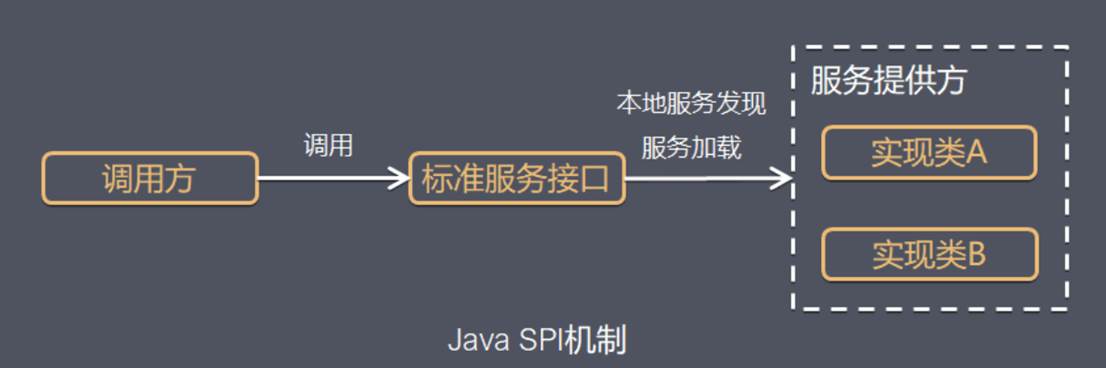
当服务的提供者提供了一种接口的实现之后,需要在classpath下的 META-INF/services/ 目录里创建一个文件,文件名是以服务接口命名的,而文件里的内容是这个接口的具体的实现类。
当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,再根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader。
SPI机制的简单示例
假设现在需要一个发送消息的服务MessageService,发送消息的实现可能是基于短信、也可能是基于电子邮件、或推送通知发送消息。
接口定义:首先定义一个接口
MessageService提供两个实现类:一个通过短信发送消息,一个通过电子邮件发送消息。
配置文件:在
META-INF/services/目录下创建一个配置文件,文件名为MessageService,全限定名com.example.MessageService,文件内容为接口的实现类的全限定名。加载服务实现:在应用程序中,通过
ServiceLoader动态加载并使用这些实现类。
运行时,ServiceLoader 会发现并加载配置文件中列出的所有实现类,并依次调用它们的 sendMessage 方法。
由于在 配置文件 写了两个实现类,因此两个实现类都会执行 sendMessage 方法。
这就是因为ServiceLoader.load(Search.class)在加载某接口时,会去 META-INF/services 下找接口的全限定名文件,再根据里面的内容加载相应的实现类。
这就是spi的思想,接口的实现由provider实现,provider只用在提交的jar包里的META-INF/services下根据平台定义的接口新建文件,并添加进相应的实现类内容就好。
SPI机制的应用
JDBC DriverManager
在JDBC4.0之前,开发连接数据库的时候,通常会用Class.forName("com.mysql.jdbc.Driver")这句先加载数据库相关的驱动,然后再进行获取连接等的操作。而JDBC4.0之后不需要用Class.forName("com.mysql.jdbc.Driver")来加载驱动,直接获取连接就可以了,原因就是现在使用了Java的SPI扩展机制来实现。
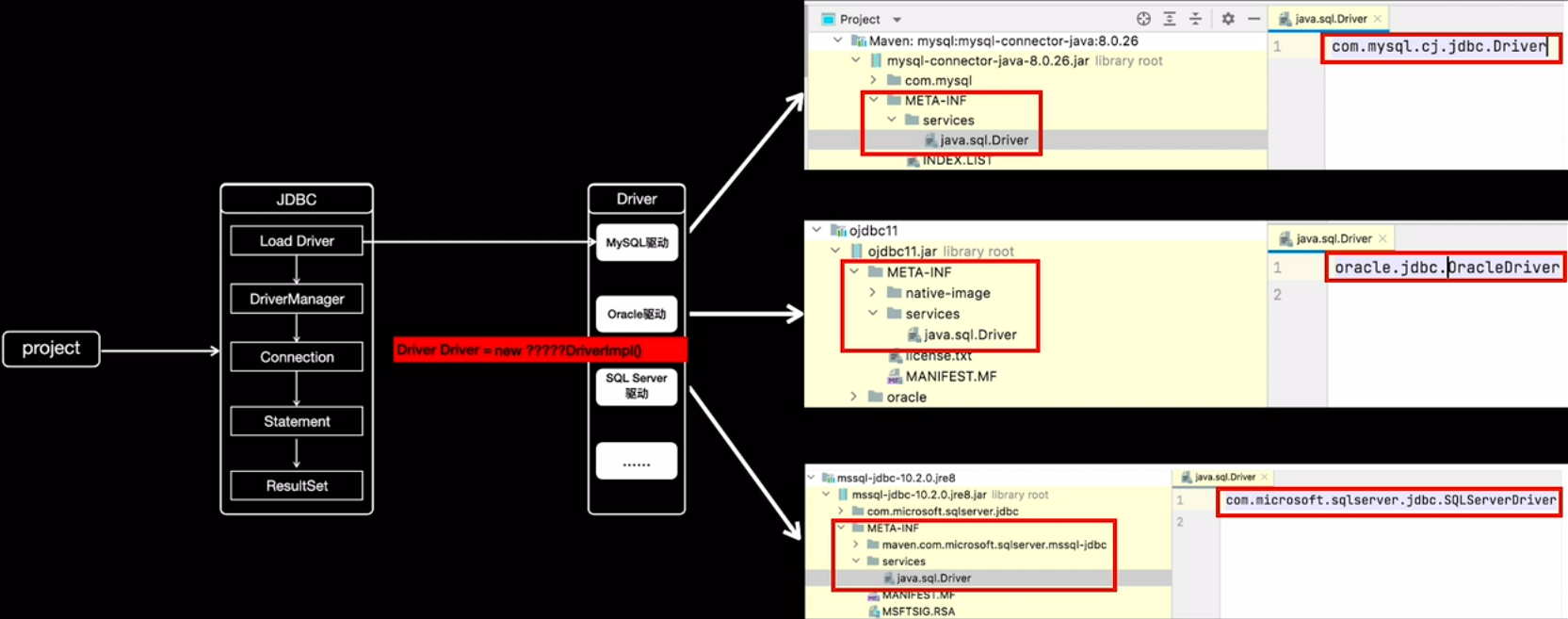 如上图所示:
如上图所示:
首先在java中定义了接口 java.sql.Driver,并没有具体的实现,具体的实现都是由不同厂商来提供的。
在mysql的jar包mysql-connector-java-8.0.26.jar中,可以找到 META-INF/services 目录,该目录下会有一个名字为 java.sql.Driver 的文件,文件内容是com.mysql.cj.jdbc.Driver,这里面的内容就是mysql针对Java中定义的接口的实现。
同样在ojdbc的jar包ojdbc11.jar中,也可以找到同样的配置文件,文件内容是 oracle.jdbc.OracleDriver,这是oracle数据库对Java的java.sql.Driver的实现。
使用方法
而现在Java中写连接数据库的代码的时候,不需要再使用Class.forName("com.mysql.jdbc.Driver")来加载驱动了,直接获取连接就可以了:
这里并没有涉及到spi的使用,看下面源码。
源码实现
上面的使用方法,就是普通的连接数据库的代码,实际上并没有涉及到 SPI 的东西,但是有一点可以确定的是,我们没有写有关具体驱动的硬编码Class.forName("com.mysql.jdbc.Driver")!
而上面的代码就可以直接获取数据库连接进行操作,但是跟SPI有啥关系呢? 既然上面代码没有加载驱动的代码,那实际上是怎么去确定使用哪个数据库连接的驱动呢?
这里就涉及到使用Java的SPI 扩展机制来查找相关驱动的东西了,关于驱动的查找其实都在DriverManager中,DriverManager是Java中的实现,用来获取数据库连接,源码如下:
上面的代码主要步骤是:
从系统变量中获取有关驱动的定义。
使用SPI来获取驱动的实现。
遍历使用SPI获取到的具体实现,实例化各个实现类。
根据第一步获取到的驱动列表来实例化具体实现类。
- 第二步:使用SPI来获取驱动的实现,对应的代码是:
这里封装了接口类型和类加载器,并初始化了一个迭代器。
- 第三步:遍历获取到的具体实现,实例化各个实现类,对应的代码如下:
在遍历的时候,首先调用driversIterator.hasNext()方法,这里会搜索classpath下以及jar包中所有的META-INF/services目录下的java.sql.Driver文件,并找到文件中的实现类的名字,此时并没有实例化具体的实现类(ServiceLoader具体的源码实现在下面)。
然后是调用driversIterator.next();方法,此时就会根据驱动名字具体实例化各个实现类了。现在驱动就被找到并实例化了。
Common-Logging
common-logging(也称Jakarta Commons Logging,缩写 JCL)是常用的日志库门面, 使用了SPI的方式来动态加载和配置日志实现。这种机制允许库在运行时找到合适的日志实现,而无需硬编码具体的日志库。
我们看下它是怎么通过SPI解耦的。
首先,日志实例是通过LogFactory的getLog(String)方法创建的:
LogFatory是一个抽象类,它负责加载具体的日志实现,getFactory()方法源码如下:
可以看出,抽象类LogFactory加载具体实现的步骤如下:
从vm系统属性org.apache.commons.logging.LogFactory
使用SPI服务发现机制,发现org.apache.commons.logging.LogFactory的实现
查找classpath根目录commons-logging.properties的org.apache.commons.logging.LogFactory属性是否指定factory实现
使用默认factory实现,org.apache.commons.logging.impl.LogFactoryImpl
LogFactory的getLog()方法返回类型是org.apache.commons.logging.Log接口,提供了从trace到fatal方法。可以确定,如果日志实现提供者只要实现该接口,并且使用继承自org.apache.commons.logging.LogFactory的子类创建Log,必然可以构建一个松耦合的日志系统。
Spring中SPI机制
在springboot的自动装配过程中,最终会加载META-INF/spring.factories文件,主要通过以下几个步骤实现:
服务接口定义: Spring 定义了许多服务接口,如
org.springframework.boot.autoconfigure.EnableAutoConfiguration。服务提供者实现: 各种具体的模块和库会提供这些服务接口的实现,如各种自动配置类。
服务描述文件: 在实现模块的 JAR 包中,会有一个
META-INF/spring.factories文件,这个文件中列出了该 JAR 包中实现的自动配置类。服务加载: Spring Boot 在启动时加载
spring.factories文件,并实例化这些文件中列出的实现类。
Spring Boot 使用 SpringFactoriesLoader 来加载 spring.factories 文件中列出的所有类,并将它们注册到应用上下文中。需要注意的是,其实这里不仅仅是会去ClassPath路径下查找,会扫描所有路径下的Jar包,只不过这个文件只会在Classpath下的jar包中。
通过 SPI 机制和 spring.factories 文件的配合,Spring Boot 实现了模块化和自动配置的能力。开发者可以通过定义自动配置类并在 spring.factories 文件中声明它们,从而实现模块的独立和松耦合。这种机制不仅简化了配置和启动过程,还提升了应用的可扩展性和维护性。
SPI 机制通常怎么使用
看完上面的几个例子解析,应该都能知道大概的流程了:
定义标准:定义标准,就是定义接口。比如接口java.sql.Driver
具体厂商或者框架开发者实现:厂商或者框架开发者开发具体的实现: 在META-INF/services目录下定义一个名字为接口全限定名的文件,比如java.sql.Driver文件,文件内容是具体的实现名字,比如me.cxis.sql.MyDriver。写具体的实现me.cxis.sql.MyDriver,都是对接口Driver的实现。
具体使用:引用具体厂商的jar包来实现我们的功能:
使用规范:
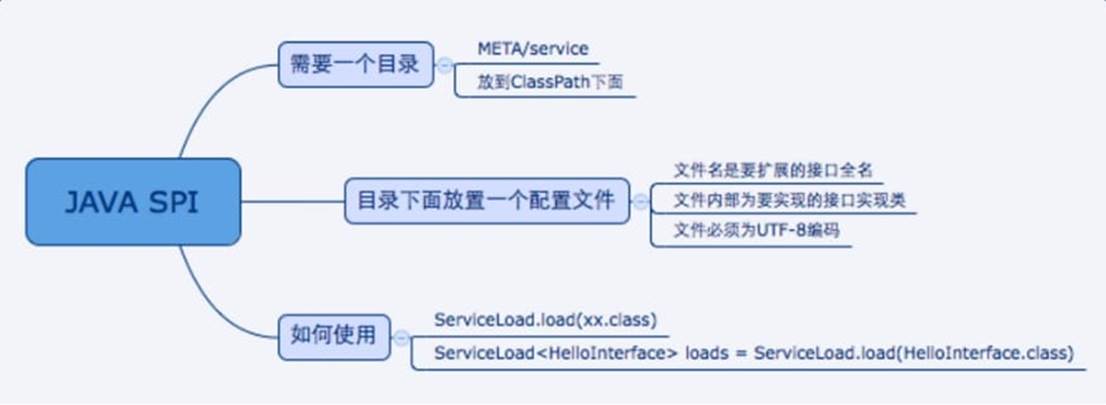
SPI机制实现原理
那么问题来了: 怎么样才能加载这些SPI接口的实现类呢,真正的原因是Java的类加载机制! SPI接口属于java rt核心包,只能由启动类加载器BootStrap classLoader加载,而第三方jar包是用户classPath路径下,根据类加载器的可见性原则:启动类加载器无法加载这些jar包,也就是没法向下委托,所以spi必须打破这种传统的双亲委派机制,通过自定义的类加载器来加载第三方jar包下的spi接口实现类!
JDK中ServiceLoader方法的具体实现:
首先,ServiceLoader实现了Iterable接口,所以它有迭代器的属性,这里主要都是实现了迭代器的 hasNext 和 next 方法。这里主要都是调用的lookupIterator的相应hasNext和next方法,lookupIterator是懒加载迭代器。
其次,LazyIterator 中的 hasNext 方法,静态变量PREFIX就是”META-INF/services/”目录,这也就是为什么需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件。
最后,通过反射方法Class.forName()加载类对象,并用newInstance方法将类实例化,并把实例化后的类缓存到providers对象中,(LinkedHashMap<String,S>类型)然后返回实例对象。
所以可以看到ServiceLoader不是实例化以后,就去读取配置文件中的具体实现,并进行实例化。而是等到使用迭代器去遍历的时候,才会加载对应的配置文件去解析,调用hasNext方法的时候会去加载配置文件进行解析,调用next方法的时候进行实例化并缓存。
所有的配置文件只会加载一次,服务提供者也只会被实例化一次,重新加载配置文件可使用reload方法。
JDK SPI机制的缺陷
通过上面的解析,可以发现,我们使用SPI机制的缺陷:
获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。
多个并发多线程使用 ServiceLoader 类的实例是不安全的