cat命令 - 在终端设备上显示文件内容
cat命令来自英文词组concatenate files and print的缩写,其功能是在终端设备上显示文件内容。在Linux系统中有很多用于查看文件内容的命令,例如more、tail、head等,每个命令都有各自的特点。cat命令适合查看内容较少的纯文本文件。 对于内容较多的文件,使用cat命令查看后会在屏幕上快速滚屏,用户往往看不清所显示的具体内容,只好按Ctrl+C组合键中断命令执行,所以对于大文件,干脆用more命令显示吧。
语法格式
常用参数:
-n:显示行号,会在输出的每一行前加上行号。-b:显示行号,但只对非空行进行编号。-s:压缩连续的空行,只显示一个空行。-E:在每一行的末尾显示$符号。-T:将 Tab 字符显示为^I。-v:显示一些非打印字符。
使用说明:
显示文件内容:
cat filename会将指定文件的内容输出到终端上。连接文件:
cat file1 file2 > combined_file可以将 file1 和 file2 的内容连接起来,并将结果输出到 combined_file 中。创建文件:可以使用
cat命令来创建文件,例如cat > filename,然后你可以输入文本,按Ctrl+D来保存并退出。在终端显示文件:可以将
cat与管道(|)结合使用,用来显示其他命令的输出,例如ls -l | cat会将ls -l的输出通过cat打印到终端上。
实例
**查看文件内容:**显示文件 filename 的内容。
**创建文件:**将标准输入重定向到文件 filename,覆盖该文件的内容。
**追加内容到文件:**将标准输入追加到文件 filename 的末尾。
**连接文件:**将 file1 和 file2 的内容合并到 file3 中。
**显示多个文件的内容:**同时显示 file1 和 file2 的内容。
**使用管道:**将 cat 命令的输出作为另一个命令的输入。
**查看文件的最后几行:**显示文件 filename 的最后 10 行。
**使用 -n 选项显示行号:**显示文件 filename 的内容,并在每行的前面加上行号。
使用 -b 选项仅显示非空行的行号:
**使用 -s 选项合并空行:**显示文件 filename 的内容,并合并连续的空行。
**使用 -t 选项显示制表符:**显示文件 filename 的内容,并用 ^I 表示制表符。
**使用 -e 选项显示行结束符:**显示文件 filename 的内容,并用 $ 表示行结束。
把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里:
把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)之后将内容附加到 textfile3 文档里:
清空 /etc/test.txt 文档内容:
cat 也可以用来制作镜像文件。例如要制作软盘的镜像文件,将软盘放好后输入:
相反的,如果想把 image file 写到软盘,输入:
注:
OUTFILE :指输出的镜像文件名。
IMG_FILE :指镜像文件。
若从镜像文件写回 device 时,device 容量需与相当。
通常用制作开机磁片。
rm命令 - 删除文件或目录
rm命令来自英文单词remove的缩写,中文译为“消除”,其功能是删除文件或目录,一次可以删除多个文件,或递归删除目录及其内的所有子文件。
rm也是一个很危险的命令,使用的时候要特别当心,尤其对于新手更要格外注意。例如,执行rm -rf /*命令会清空系统中所有的文件,甚至无法恢复回来。所以我们在执行之前一定要再次确认在在哪个目录中、到底要删除什么文件,考虑好后再敲击Enter键,要时刻保持清醒的头脑。
语法格式
常用参数:
-i :删除前逐一询问确认。
-f :即使原档案属性设为唯读,亦直接删除,无需逐一确认。
-r :将目录及以下之档案亦逐一删除。
实例
删除文件可以直接使用rm命令,若删除目录则必须配合选项"-r",例如:
删除当前目录下的所有文件及目录,命令行为:
文件一旦通过rm命令删除,则无法恢复,所以必须格外小心地使用该命令。
echo命令 - 输出字符串或提取后的变量值
echo命令的功能是在终端设备上输出指定字符串或变量提取后的值,能够给用户一些简单的提醒信息,亦可以将输出的指定字符串内容同管道符一起传递给后续命令作为标准输入信息进行二次处理,还可以同输出重定向符一起操作,将信息直接写入文件。如需提取变量值,需在变量名称前加入$符号,变量名称一般均为大写形式。
语法格式:
实例
- 显示普通字符串:
这里的双引号完全可以省略,以下命令与上面实例效果一致:
- 显示转义字符
结果将是:
同样,双引号也可以省略
- 显示变量
read 命令从标准输入中读取一行,并把输入行的每个字段的值指定给 shell 变量
以上代码保存为 test.sh,name 接收标准输入的变量,结果将是:
- 显示换行
输出结果:
- 显示不换行
输出结果:
显示结果定向至文件
原样输出字符串,不进行转义或取变量(用单引号)
输出结果:
- 显示命令执行结果
注意: 这里使用的是反引号 `, 而不是单引号 ’。
结果将显示当前日期
tail命令 - 查看文件尾部内容
tail命令的功能是查看文件尾部内容,例如默认会在终端界面上显示指定文件的末尾10行,如果指定了多个文件,则会在显示的每个文件内容前面加上文件名来加以区分。高阶玩法的-f参数的作用是持续显示文件的尾部最新内容,类似于机场候机厅的大屏幕,总会把最新的消息展示给用户,对阅读日志文件尤为适合,再也不需要手动刷新了。
语法格式
常用参数:
-f: 循环读取
-q :不显示处理信息
-v :显示详细的处理信息
-c<数目> :显示的字节数
-n<行数> :显示文件的尾部 n 行内容
–pid=PID :与-f合用,表示在进程ID,PID死掉之后结束
-q, –quiet, –silent :从不输出给出文件名的首部
-s, –sleep-interval=S :与-f合用,表示在每次反复的间隔休眠S秒
实例
要显示 notes.log 文件的最后 10 行,请输入以下命令:
要跟踪名为 notes.log 的文件的增长情况,请输入以下命令:
此命令显示 notes.log 文件的最后 10 行。当将某些行添加至 notes.log 文件时,tail 命令会继续显示这些行。 显示一直继续,直到您按下(Ctrl-C)组合键停止显示。
显示文件 notes.log 的内容,从第 20 行至文件末尾:
显示文件 notes.log 的最后 10 个字符:
rmdir命令 - 删除空目录文件
rmdir命令来自英文词组remove directory的缩写,其功能是删除空目录文件。rmdir命令仅能删除空内容的目录文件,如需删除非空目录时,需要使用带有-R参数的rm命令进行操作。而rmdir命令的递归删除操作(-p参数使用)并不意味着能删除目录中已有的文件,而是要求每个子目录都必须是空的。
语法格式
- -p 是当子目录被删除后使它也成为空目录的话,则顺便一并删除。
实例
将工作目录下,名为 AAA 的子目录删除 :
在工作目录下的 BBB 目录中,删除名为 Test 的子目录。若 Test 删除后,BBB 目录成为空目录,则 BBB 亦予删除。
grep命令 - 强大的文本搜索工具
grep命令来自英文词组global search regular expression and print out the line的缩写,意思是用于全面搜索的正则表达式,并将结果输出。人们通常会将grep命令与正则表达式搭配使用,参数作为搜索过程中的补充或对输出结果的筛选,命令模式十分灵活。
与之容易混淆的是egrep命令和fgrep命令。如果把grep命令当作标准搜索命令,那么egrep则是扩展搜索命令,等价于grep -E命令,支持扩展的正则表达式。而fgrep则是快速搜索命令,等价于grep -F命令,不支持正则表达式,直接按照字符串内容进行匹配。
语法格式
pattern - 表示要查找的字符串或正则表达式。
files - 表示要查找的文件名,可以同时查找多个文件,如果省略 files 参数,则默认从标准输入中读取数据。
常用参数:
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
更多参数说明:
-a 或 –text : 不要忽略二进制的数据。
-A<显示行数> 或 –after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 –byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> 或 –before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 –count : 计算符合样式的列数。
-C<显示行数> 或 –context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> 或 –directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> 或 –regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
-E 或 –extended-regexp : 将样式为延伸的正则表达式来使用。
-f<规则文件> 或 –file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 –fixed-regexp : 将样式视为固定字符串的列表。
-G 或 –basic-regexp : 将样式视为普通的表示法来使用。
-h 或 –no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 –with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 –ignore-case : 忽略字符大小写的差别。
-l 或 –file-with-matches : 列出文件内容符合指定的样式的文件名称。
-L 或 –files-without-match : 列出文件内容不符合指定的样式的文件名称。
-n 或 –line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 –only-matching : 只显示匹配PATTERN 部分。
-q 或 –quiet或–silent : 不显示任何信息。
-r 或 –recursive : 此参数的效果和指定"-d recurse"参数相同。
-s 或 –no-messages : 不显示错误信息。
-v 或 –invert-match : 显示不包含匹配文本的所有行。
-V 或 –version : 显示版本信息。
-w 或 –word-regexp : 只显示全字符合的列。
-x –line-regexp : 只显示全列符合的列。
-y : 此参数的效果和指定"-i"参数相同。
实例
在文件 file.txt 中查找字符串 “hello”,并打印匹配的行:
在文件夹 dir 中递归查找所有文件中匹配正则表达式 “pattern” 的行,并打印匹配行所在的文件名和行号:
在标准输入中查找字符串 “world”,并只打印匹配的行数:
在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
结果如下所示:
- 以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
输出结果如下:
- 反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
结果如下所示:
sed命令 - 批量编辑文本文件
sed命令来自英文词组stream editor的缩写,其功能是利用语法/脚本对文本文件进行批量的编辑操作。sed命令最初由贝尔实验室开发,后被众多Linux系统集成,能够通过正则表达式对文件进行批量编辑,让重复性的工作不再浪费时间。
语法格式
常用参数:
-e<script>或–expression=<script> 以选项中指定的script来处理输入的文本文件。
-f<script文件>或–file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h或–help 显示帮助。
-n或–quiet或–silent 仅显示script处理后的结果。
-V或–version 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何东东;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!例如 1,20s/old/new/g 就是啦!
实例
我们先创建一个 testfile 文件,内容如下:
- 在 testfile 文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
使用 sed 命令后,输出结果如下:
- 以行为单位的新增/删除:
将 testfile 的内容列出并且列印行号,同时,请将第 2~5 行删除!
sed 的动作为 2,5d,那个 d 是删除的意思,因为删除了 2-5 行,所以显示的数据就没有 2-5 行了, 另外,原本应该是要下达 sed -e 才对,但没有 -e 也是可以的,同时也要注意的是, sed 后面接的动作,请务必以 ’…’ 两个单引号括住喔!
只要删除第 2 行:
要删除第 3 到最后一行:
在第二行后(即加在第三行) 加上drink tea? 字样:
如果是要在第二行前,命令如下:
如果是要增加两行以上,在第二行后面加入两行字,例如 Drink tea or ….. 与 drink beer?
每一行之间都必须要以反斜杠 \ 来进行新行标记。上面的例子中,我们可以发现在第一行的最后面就有 \ 存在。
- 以行为单位的替换与显示
将第 2-5 行的内容取代成为 No 2-5 number 呢?
透过这个方法就能够将数据整行取代了。
仅列出 testfile 文件内的第 5-7 行:
可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示。
- 数据的搜寻并显示
搜索 testfile 有 oo 关键字的行:
如果 root 找到,除了输出所有行,还会输出匹配行。
- 数据的搜寻并删除
删除 testfile 所有包含 oo 的行,其他行输出
- 数据的搜寻并执行命令
搜索 testfile,找到 oo 对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把 oo 替换为 kk,再输出这行:
最后的 q 是退出。
- 数据的查找与替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的查找与替换<。
sed 的查找与替换的与 vi 命令类似,语法格式如下:
将 testfile 文件中每行第一次出现的 oo 用字符串 kk 替换,然后将该文件内容输出到标准输出:
g 标识符表示全局查找替换,使 sed 对文件中所有符合的字符串都被替换,修改后内容会到标准输出,不会修改原文件:
选项 i 使 sed 修改文件:
批量操作当前目录下以 test 开头的文件:
接下来使用 /sbin/ifconfig 查询 IP:
本机的 ip 是 192.168.1.100。
将 IP 前面的部分予以删除:
接下来则是删除后续的部分,即:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0。
将 IP 后面的部分予以删除:
- 多点编辑
一条 sed 命令,删除 testfile 第三行到末尾的数据,并把 HELLO 替换为 RUNOOB :
-e 表示多点编辑,第一个编辑命令删除 testfile 第三行到末尾的数据,第二条命令搜索 HELLO 替换为 RUNOOB。
- 直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由于这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试! 我们还是使用文件 regular_express.txt 文件来测试看看吧!
regular_express.txt 文件内容如下:
利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
利用 sed 直接在 regular_express.txt 最后一行加入 # This is a test:
由于 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增 # This is a test!
sed 的 -i 选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,甚至不需要使用 vim 去修订!
awk命令 - 强大的文本分析工具
awk命名源自于它的三大作者名字的首字母,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。awk是一个强大的文本分析工具,相当于grep的查找和sed的编辑功能,根据分隔符对每行数据切片,切开的部分在进行各种分析处理,处理的数据可以来自标准输入、一个或多个文件,或其它命令的输出。常用作脚本使用
语法格式
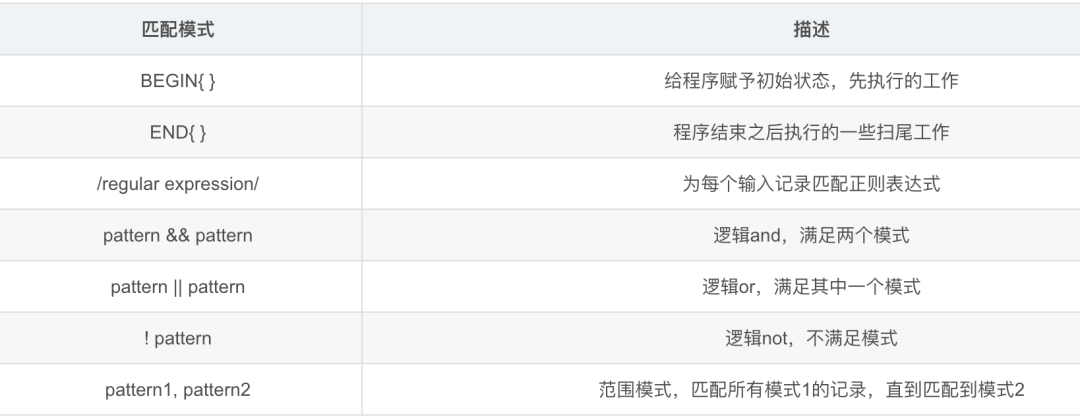
BEGIN、END是AWK的关键字部,因此必须大写,属于可选部分。BEGIN命令快是处理每行数据之前执行的操作。END命令是处理完每行数据之后执行的操作,常用于打印输出统计结果等。
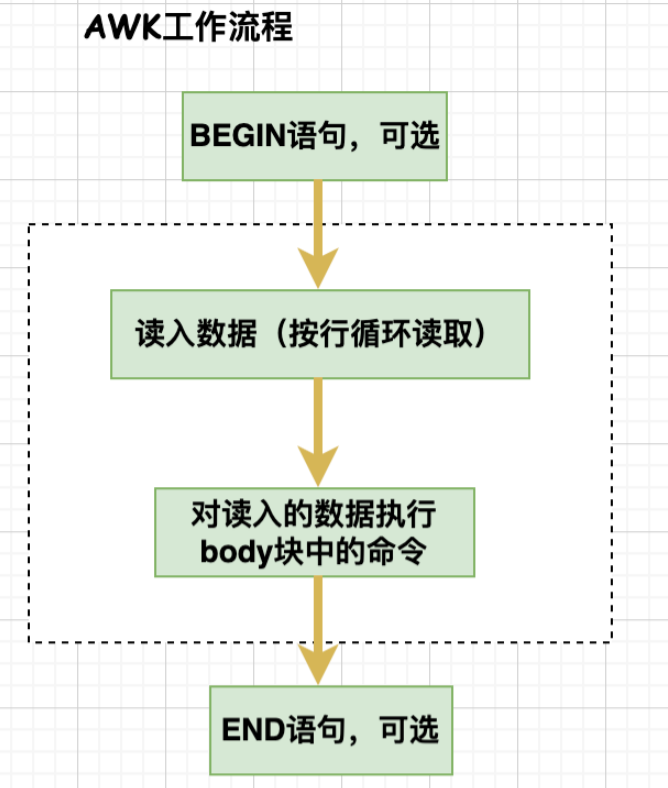
pattern:匹配模式,表示AWK在数据中查找的内容
action:找到匹配内容时所执行的一系列命令
 awk常用参数
awk常用参数
-F:指定分隔符,默认使用空格进行分隔
-V:赋值一个用户定义变量
awk命令中常用的内置变量
n:比如1 23,取第几列信息
NF:浏览记录的域的个数, 根据分隔符分割后的列数
$NF: 取最后一列
$(NF-n): 取倒数第几列
$0: 取所有列的信息
FILENAME:awk浏览的文件名
NR:行号
RS:行分隔符,默认是换行;
FS:列分隔符,默认是空格和制表符;
OFS:输出列分隔符,用于打印时分割字段,默认为空格
ORS:输出行分隔符,用于打印时分割记录,默认为换行符
实例
打印第一列
打印第二行的内容
打印第5行到第10行的第1列
指定多个分隔符
统计passwd文件每行的行号、列数、行内容
打印以mysql开头的行
过滤IP
打印字符串长度大于3的单词
以字符串
diffres:作为字段分隔符(-F),提取每行中该分隔符后的第二部分内容;对awk提取的内容按字典序升序排序,使相同内容相邻排列,为后续uniq去重做准备;对uniq的统计结果按数值(-n)降序(-r)排序,最终显示频率从高到低的结果