介绍
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字,无法直接创建)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高;底层使用双向链表存储
 LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装。
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装。
底层实现
底层数据结构
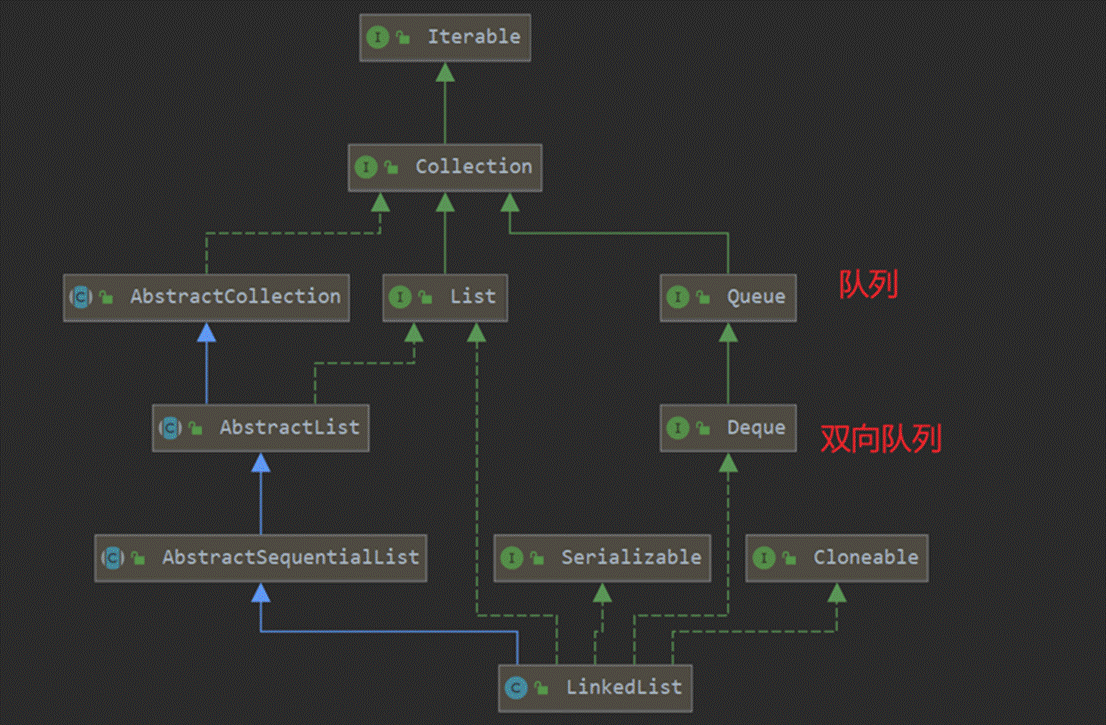
LinkedList底层通过双向链表实现。双向链表的每个节点用内部类Node表示。LinkedList通过first和last引用分别指向链表的第一个和最后一个元素。注意这里没有所谓的哑元(也就是没有虚拟变量),当链表为空的时候first和last都指向null。
其中Node是私有的内部类:
构造函数
getFirst(), getLast()
获取第一个元素, 和获取最后一个元素:
get方法
get方法是根据索引获取元素的
removeFirst(), removeLast(), remove(e), remove(index)
remove()方法也有两个版本
删除跟指定元素相等的第一个元素remove(Object o)
删除指定下标处的元素remove(int index)
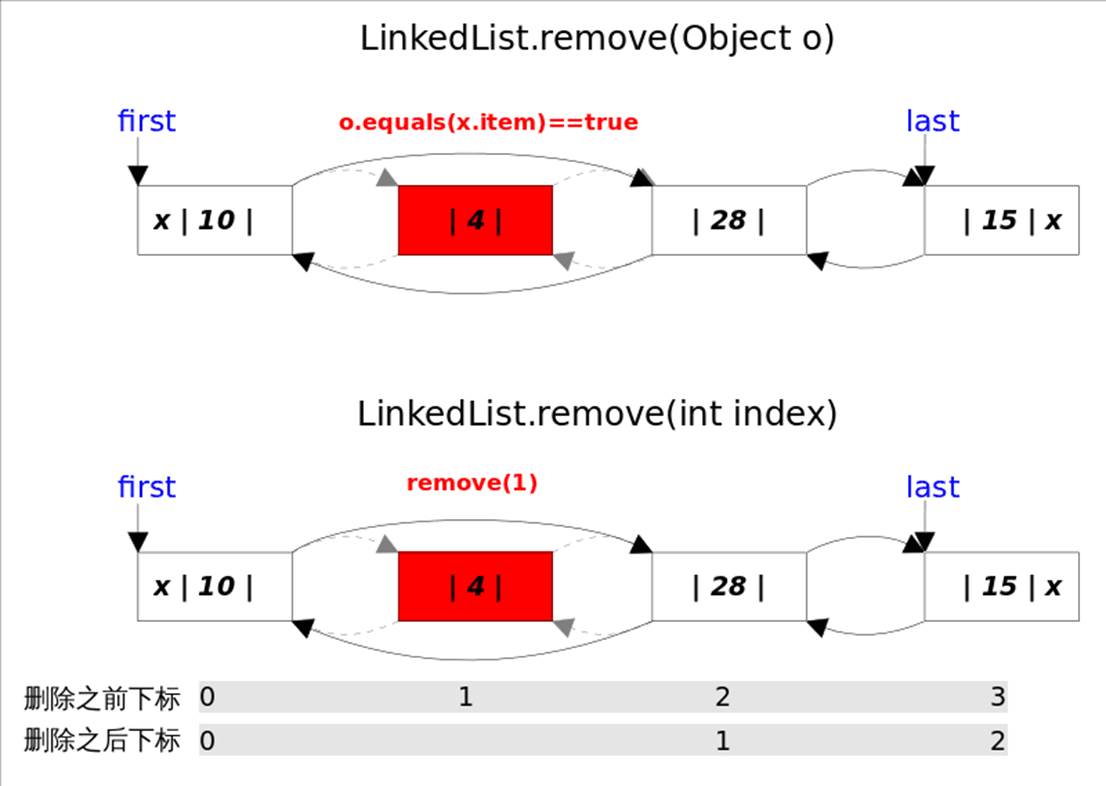 删除元素:指的是删除第一次出现的这个元素, 如果没有这个元素,则返回false;判断的依据是equals方法, 如果equals,则直接unlink这个node;
由于LinkedList可存放null元素,故也可以删除第一次出现null的元素;
删除元素:指的是删除第一次出现的这个元素, 如果没有这个元素,则返回false;判断的依据是equals方法, 如果equals,则直接unlink这个node;
由于LinkedList可存放null元素,故也可以删除第一次出现null的元素;
linklist是有序的,可重复存储数据的,并且可以存储null值,但remove方法在找到需要删除的元素时,就return了,因此只能删除找到的第一个元素
add方法
add()方法有两个版本:
add(E e),该方法在LinkedList的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间。只需要简单修改几个相关引用即可;
- add(int index, E element),该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。
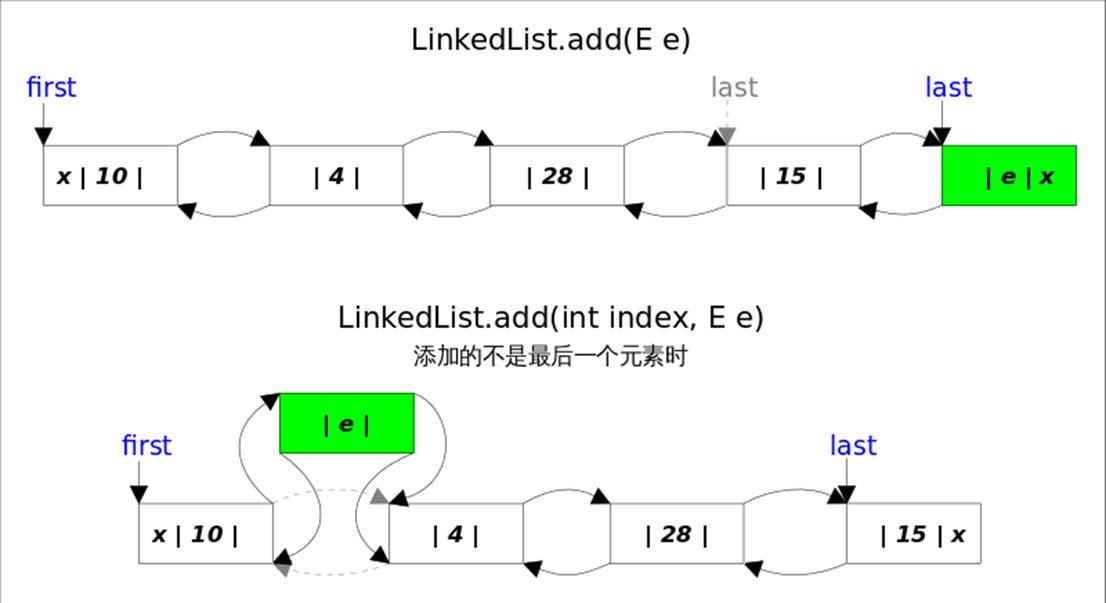 add(int index, E element),当index==size时,等同于add(E e); 如果不是,则分两步:
add(int index, E element),当index==size时,等同于add(E e); 如果不是,则分两步:
先根据index找到要插入的位置,即node(index)方法;
修改引用,完成插入操作。
上面代码中的node(int index)函数有一点小小的trick,因为链表双向的,可以从开始往后找,也可以从结尾往前找,具体朝那个方向找取决于条件index < (size >> 1),也即是index是靠近前端还是后端。从这里也可以看出,linkedList通过index查询元素的效率没有arrayList高。
addAll()
addAll(index, c) 实现方式并不是直接调用add(index,e)来实现,主要是因为效率的问题,另一个是fail-fast中modCount只会增加1次;
clear()
这里是将node之间的引用关系都变成null,这样GC可以在年轻代回收元素了
注意:有些同学可能注意到这里的判定条件是x != null,但是 LinkedList 是可以设置null值的,那是不是当链表中有null的元素,并且爱clear遍历到元素为null时,条件 x != null就为false了,那就不会继续执行,也就是后续的元素都无法置为空了?
实际上不是的,这里的x != null是没有这个元素,而LinkedList 中可以设置null值是指,x.item = null,也就是有Node,但是Node的item属性为null
Positional Access 方法
通过index获取元素
将某个位置的元素重新赋值:
将元素插入到指定index位置:
删除指定位置的元素:
其它位置的方法:
查找操作
查找操作的本质是查找元素的下标:
查找第一次出现的index, 如果找不到返回-1;
查找最后一次出现的index, 如果找不到返回-1;
LinkedList 存在的性能问题
在现代计算机架构下,数组在绝大多数场景下都比链表快,包括那些理论上链表应该占优的场景。
原因很简单:
- CPU 缓存命中率:数组很高,链表很低
- 预取机制:CPU 能预测数组的下一个访问位置,但对链表不可以
- 链表的「伪O(1)」插入删除
- 内存访问模式:数组线性访问,链表随机跳跃
CPU缓存行
CPU 缓存不是按字节加载的,而是按照缓存行为单位,通常是 64 字节。
当你访问一个 int(4字节)时,CPU 会把它附近的 60 字节一起加载到缓存
对数组来说,这就是天赐良机:
一次内存访问,换来 16 次缓存命中。 这就是数组的很快的原因。
但链表的每个节点可能分散在内存的各个角落,从而导致每次都是 Cache Miss…
你加载了一个缓存行,但只用了其中 8-16 字节(一个指针),剩下的 50 多字节完全浪费。缓存利用率不到 20%。
这就是为什么链表在实际中慢得要死——不是因为指针操作慢,而是因为每次访问都在等内存
计科里有两个重要的概念:
空间局部性:访问了地址 X,很可能接下来访问 X+1, X+2…
时间局部性:访问了地址 X,短时间内可能再次访问 X
数组就可以做到两者兼具:
遍历时,天然的空间局部性
多次访问同一个元素,时间局部性也很好
链表只有时间局部性(如果你反复访问同一个节点的话),空间局部性基本为零。
CPU预取机制
当 CPU 检测到你在顺序访问内存时(比如遍历数组),它会主动把后面的数据加载到缓存,在你真正访问之前就准备好了。
这就是为什么遍历大数组时,几乎感觉不到内存延迟——CPU 已经提前帮你准备好了
但链表呢?CPU 看着你的访问模式:
完全随机,毫无规律。预取器直接放弃治疗。每次访问都是实打实的内存延迟。
关闭 CPU 预取功能后,数组遍历速度能慢 5-10 倍;但链表遍历几乎没变化——因为本来就没预取啊……
插入删除
- 链表的「伪O(1)」插入删除
书里说链表插入删除是 O(1),但那是建立在「你已经找到了目标位置」的前提下!
但在现实中,你几乎总是需要先找到插入位置:
总复杂度还是 O(n)的 而且是个缓存友好度极差的 O(n)。
- 数组的相对没那么慢的插入删除
数组插入需要移动元素,理论上是 O(n):
但注意,这个 O(n) 的移动操作是连续内存拷贝,完全在缓存中完成!
内存分配
数组通常是一次分配一大块连续内存或者预分配后逐渐增长。而链表每次插入都需要 new 一个节点,每次删除都需要 delete。
new 和 delete 可不是免费的:
需要找到合适大小的空闲内存块
可能触发系统调用
需要维护内存管理的元数据
可能导致内存碎片
从Java的角度来看,LinkedList 需要创建一个 Node 对象,当执行 new 操作的时候,其过程是非常慢的,会经历两个过程:类加载过程 、对象创建过程
- 类加载过程
- 会先判断这个类是否已经初始化,如果没有初始化,会执行类的加载过程
- 类的加载过程:加载、验证、准备、解析、初始化等等阶段,之后会执行
<cnit>方法,初始化静态变量,执行静态代码块等等 - 对象创建过程
- 如果类已经初始化了,直接执行对象的创建过程
- 对象的创建过程:在堆内存中开辟一块空间,给开辟空间分配一个地址,之后执行初始化,会执行
<cnit>方法,初始化普通变量,调用普通代码块
高频的小对象分配(链表节点通常很小),new 的开销能占到总时间的 30-50%。而且,malloc/new 分配的内存往往是分散的,进一步恶化了缓存局部性。数组动态扩容虽然偶尔需要拷贝,但平摊下来,分配开销远小于链表。
链表真实使用场景
链表作为一种特殊的数据结构在某些特定场景下还是有价值的
- 真正的 O(1) 插入删除
如果你已经持有某个节点的指针,想在这个位置插入或删除,那链表确实是 O(1),而且这个 O(1) 很实在。比如 LRU 缓存的实现,需要频繁地把节点移到链表头部,这种场景下链表就很合适。
- 不需要遍历的情况
像队列、栈这种只操作头尾的数据结构,链表还凑合。虽然数组实现的队列(环形队列)通常还是更快……
- 内存受限而且大小不确定
数组需要连续内存,如果内存碎片化严重,可能分配不出来。链表的离散存储在这种极端情况下可能是唯一选择。
但说实话,这种场景在现代系统中越来越少见了。
- 或者在某些特殊的算法
有些算法天生就是为链表设计的,比如一些图算法中的邻接表。强行用数组改写可能反而更复杂。
但我感觉链表的适用场景其实是越来越窄了。很多老项目里用链表的代码,现在重写成数组后,性能都能有质的提升。