在微服务架构中,服务与服务之间通过远程调用的方式进行通信,一旦某个被调用的服务发生了故障,其依赖服务也会发生故障,此时就会发生故障的蔓延,最终导致灾难性雪崩效应。服务保护就是为了保证服务的稳定性而出生的一套保护方案
雪崩问题
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
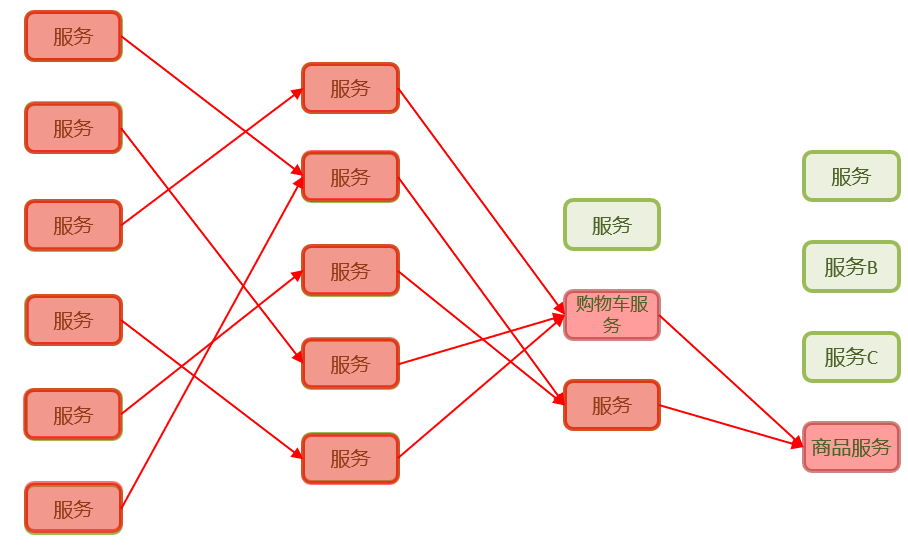
产生的原因?
微服务相互调用,服务提供者出现故障或阻塞。
服务调用者没有做好异常处理,导致自身故障。
调用链中的所有服务级联失败,导致整个集群故障
解决问题的思路?
超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。
舱壁模式:限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。
熔断降级:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
请求限流
限制访问接口的请求的并发量,避免服务因流量激增出现故障。

网关限流
Nginx 限流
Nginx自带了两个限流模块:
连接数限流模块 ngx_http_limit_conn_module漏桶算法实现的请求限流模块 ngx_http_limit_req_module
1、ngx_http_limit_conn_module
主要用于限制脚本攻击,如果在秒杀活动开始,一个黑客写了脚本来攻击,会造成带宽被浪费,大量无效请求产生,对于这类请求, 可以通过对 ip 的连接数进行限制。
可以在nginx_conf的http{}中加上如下配置实现限制:
2、ngx_http_limit_req_module
上面说的 是 ip 的连接数, 那么如果要控制请求数呢? 限制的方法是通过使用漏斗算法,每秒固定处理请求数,推迟过多请求。如果请求的频率超过了限制域配置的值,请求处理会被延迟或被丢弃,所以所有的请求都是以定义的频率被处理的。
怎么理解 连接数,请求数限流?
连接数限流(ngx_http_limit_conn_module = 1) 每个IP,只会接待一个,只有当这个IP 处理结束了, 才会接待下一位。(单位时间内,只有一个连接在处理)
请求数限流(ngx_http_limit_req_module) 通过
漏桶算法,按照单位时间放行请求,也不管服务器能不能处理完
怎么选择?
IP限流:可以在活动开始前进行配置,也可以用于预防脚本攻击(IP代理的情况另说)
请求数限流: 日程可以配置,保护我们的服务器在突发流量造成的崩溃
Tomcat 限流
在 Tomcat 的配置文件中, 有一个 maxThreads
结合 秒杀系统,那么在介绍系统的时候,可以说,在限流这块,从网关角度,使用了 Nginx 的 ngx_http_limit_conn_module 模块,针对 IP 在单位时间内只允许一个请求,避免用户多次请求,减轻服务的压力。在进入到订单界面后,在单位时间内,会产生多次请求, 可以使用 ngx_http_limit_req_module 模块,针对请求数做限流,避免由于 IP 限制,导致订单丢失。
除此之外,在服务上线前,针对服务器进行了最大并发的压测(如200并发),因此在 Tomcat 允许的最大请求中,设置为(300,稍微上调,有其他请求)。
服务器限流
单机限流
如果系统部署,是只有一台机器,那可以直接使用 单机限流的方案。可以使用Guava框架里的限流器,主要是基于令牌桶算法
示例代码
RateLimiter.tryAcquire() 和 RateLimiter.acquire() 两个方法都通过限流器获取令牌
集群限流
在讲集群限流前,提个思考问题:集群部署就不能用单机部署的方案了吗?
答案肯定是可以的, 可以将单机限流 的方案拓展到集群每一台机器,那么每天机器都是复用了相同的一套限流代码(RateLimit 实现)。
假设之前单机限流 500,现在集群部署了5台,那就让每台继续限流 500呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流.
那么这个方案存在什么问题呢?
流量分配不均
误限,错限
更新不及时
主要讲一下 误限 , 服务端接收到的请求,都是由 nginx 进行分发,如果某个时间段,由于请求的分配不均(60,30,10比例分配,限流50qps),会触发第一台机器的限流,而对于集群而言,整体限流阀值为 150 qps,现在 100qps 就限流了, 那肯定不行哇!因此在入口需要做好流量均分
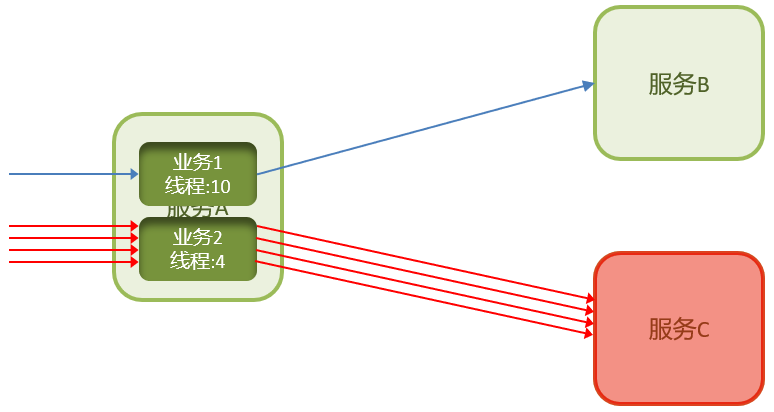
线程隔离
也叫做舱壁模式,模拟船舱隔板的防水原理。通过限定每个业务能使用的线程数量而将故障业务隔离,避免故障扩散。
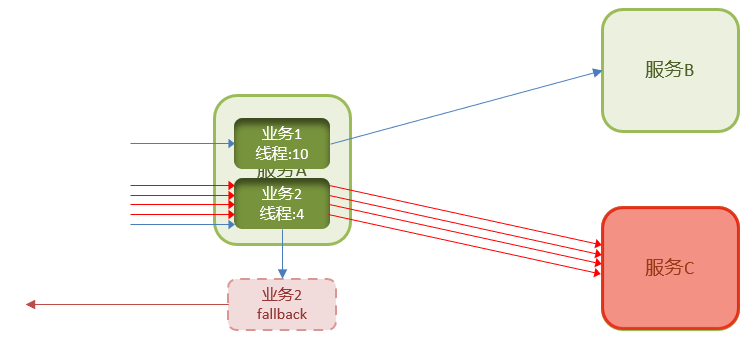
快速失败
给业务编写一个调用失败时的处理的逻辑,称为fallback。当调用出现故障(比如无线程可用)时,按照失败处理逻辑执行业务并返回,而不是直接抛出异常。
服务熔断
由断路器统计请求的异常比例或慢调用比例,如果超出阈值则会熔断该业务,则拦截该接口的请求。
熔断期间,所有请求快速失败,全都走fallback逻辑。