基础
ZooKeeper的4个节点
持久节点:默认的节点类型,一直存在于ZooKeeper中
持久顺序节点:在创建节点时,ZooKeeper根据节点创建的时间顺序对节点进行编号
临时节点:当客户端与ZooKeeper断开连接后,该进程创建的临时节点就会被删除
临时顺序节点:按时间顺序编号的临时节点
ZK分布式锁相关基础知识
zk分布式锁一般由多个节点构成(单数),采用 zab 一致性协议。因此可以将 zk 看成一个单点结构,对其修改数据其内部自动将所有节点数据进行修改而后才提供查询服务。
zk 的数据以目录树的形式,每个目录称为 znode, znode 中可存储数据(一般不超过 1M),还可以在其中增加子节点。
子节点有三种类型。序列化节点,每在该节点下增加一个节点自动给该节点的名称上自增。临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除。最后就是普通节点。
Watch 机制,client 可以监控每个节点的变化,当产生变化会给 client 产生一个事件。
实现原理
核心思想
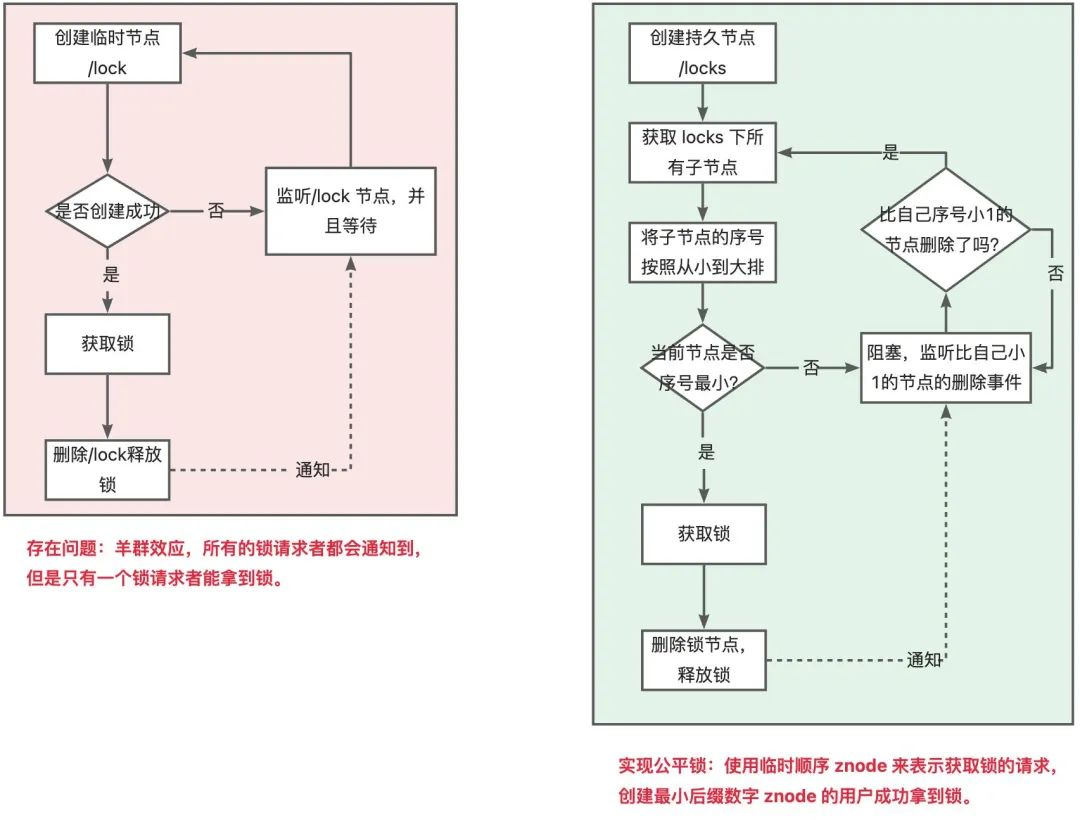
核心思想就是基于 临时顺序节点 和 Watcher(事件监听器) 实现的。
当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
客户端获取锁时,在lock节点下创建临时顺序节点。
临时是防止客户端宕机后,无法正常删除锁的情况
使用顺序节点,是因为所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好
然后获取lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
如果发现比自己小的那个节点被删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
获取锁步骤
在 /lock 节点下创建一个有序临时节点 (EPHEMERAL_SEQUENTIAL)。
判断创建的节点序号是否最小,如果是最小则获取锁成功。不是则取锁失败,然后 watch 序号比本身小的前一个节点。
当取锁失败,设置 watch 后则等待 watch 事件到来后,再次判断是否序号最小。
取锁成功则执行代码,最后释放锁(删除该节点)
释放锁步骤
成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
羊群效应和解决方法
羊群效应
在整个分布式锁的竞争过程中,大量的「Watcher通知」和「子节点列表的获取」操作重复运行,并且大多数节点的运行结果都是判断出自己当前并不是编号最小的节点,继续等待下一次通知,而不是执行业务逻辑
这就会对 ZooKeeper 服务器造成巨大的性能影响和网络冲击。更甚的是,如果同一时间多个节点对应的客户端完成事务或事务中断引起节点消失,ZooKeeper 服务器就会在短时间内向其他客户端发送大量的事件通知
解决方法
在与该方法对应的持久节点的目录下,为每个进程创建一个临时顺序节点
每个进程获取所有临时节点列表,对比自己的编号是否最小,若最小,则获得锁。
若本进程对应的临时节点编号不是最小的,则继续判断
若本进程为读请求,则向比自己序号小的最后一个写请求节点注册watch监听,当监听到该节点释放锁后,则获取锁
若本进程为写请求,则向比自己序号小的最后一个读请求节点注册watch监听,当监听到该节点释放锁后,获取锁
实现
实际项目中,推荐使用 Curator 来实现 ZooKeeper 分布式锁。Curator 是 Netflix 公司开源的一套 ZooKeeper Java 客户端框架,相比于 ZooKeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
原生API实现
Curator实现
Curator有五种锁:
InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
InterProcessMutex:分布式可重入排它锁
InterProcessReadWriteLock:分布式读写锁
InterProcessMultiLock:将多个锁作为单个实体管理的容器
InterProcessSemaphoreV2:共享信号量
Curator实现可重入锁
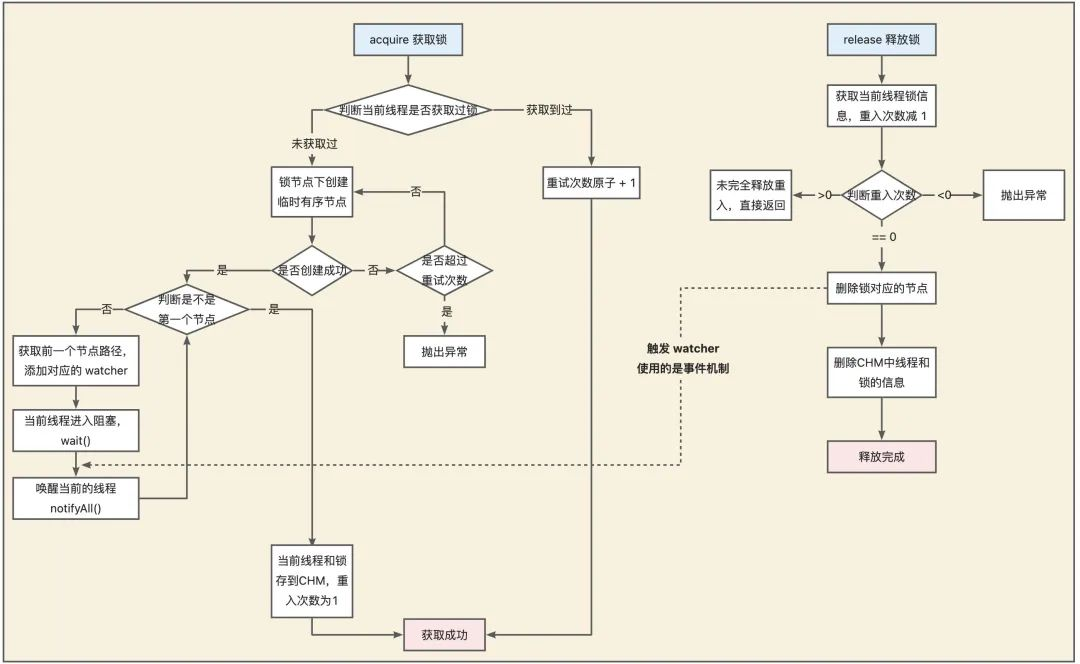 当调用 InterProcessMutex#acquire方法获取锁的时候,会调用InterProcessMutex#internalLock方法。
当调用 InterProcessMutex#acquire方法获取锁的时候,会调用InterProcessMutex#internalLock方法。
internalLock 方法会先获取当前请求锁的线程,然后从 threadData( ConcurrentMap<Thread, LockData> 类型)中获取当前线程对应的 lockData 。 lockData 包含锁的信息和加锁的次数,是实现可重入锁的关键。
第一次获取锁的时候,lockData为 null。获取锁成功之后,会将当前线程和对应的 lockData 放到 threadData 中
LockData是 InterProcessMutex中的一个静态内部类。
如果已经获取过一次锁,后面再来获取锁的话,直接就会在 if (lockData != null) 这里被拦下了,然后就会执行lockData.lockCount.incrementAndGet(); 将加锁次数加 1。
整个可重入锁的实现逻辑非常简单,直接在客户端判断当前线程有没有获取锁,有的话直接将加锁次数加 1 就可以了。
案例-模拟12306售票
 测试方法:
测试方法:
与原生 ZooKeeper API 的对比
用 Apache Curator 实现分布式锁,拥有以下优势:
简化代码:Curator 提供高级抽象,省去了大量底层代码。
可靠性:Curator 处理了很多细节和边缘情况,比如会话超时、连接重试等。
丰富的功能:除了分布式锁,Curator 还提供了常用的高级功能,如领导选举、分布式队列等。
扩展-Curator 实现Watcher 功能
可以通过 Apache Curator 来实现 ZooKeeper 的 Watcher 功能。Curator 是一个高级的 ZooKeeper 客户端,提供了许多便捷的 API。使用 Curator 实现 Watcher 功能的代码更简洁、易于维护。Curator 提供了一套 Watcher 的包装机制,使其不同于原生 ZooKeeper Watcher,Curator 能够自动处理重连和会话超时的问题,更加可靠。
使用 Curator 实现 Watcher:
首先需要创建 CuratorFramework 对象。
然后使用 Curator 的监听机制,例如 PathChildrenCache、NodeCache 或 TreeCache 来添加 Watcher。
与原生 Watcher 的不同:
Curator 提供了更高级别的抽象,简化了编程模型。
Curator 自动管理重新连接和会话超时问题。
Curator 提供了多种类型的 Cache(如 PathChildrenCache、NodeCache 和 TreeCache),方便不同场景下的使用。
优缺点
优点:
可靠性:ZooKeeper 是一个高可用的分布式协调服务,基于它的分布式锁具有较高的可靠性和稳定性。
顺序性: ZooKeeper 的有序临时节点保证了锁的获取顺序,避免了死锁和竞争问题。
避免死锁:在锁的持有者释放锁之前,其他节点无法获取锁,从而避免了死锁问题。
容错性:即使部分节点发生故障,其他节点仍然可以正常获取锁,保证了系统的稳定性。
缺点:
性能:ZooKeeper 是一个中心化的协调服务,可能在高并发场景下成为性能瓶颈。
复杂性:ZooKeeper 的部署和维护相对复杂,需要一定的运维工作。
单点故障:尽管 ZooKeeper 本身是高可用的,但如果 ZooKeeper 集群出现问题,可能会影响到基于它的分布式锁。
有序临时节点的机制确保了获取锁的顺序,避免了循环等待,从而有效地避免了死锁问题。因为任何一个客户端在释放锁之前都会删除自己的节点,从而触发下一个等待的客户端获取锁。
需要注意的是,这种机制虽然能够有效避免死锁,但也可能带来性能问题。当某个客户端释放锁时,需要触发所有等待的客户端获取锁,可能会导致较多的网络通信和监听事件。因此,在高并发情况下,需要综合考虑性能和锁的可靠性。
总的来说,基于 ZooKeeper 的分布式锁能够确保数据一致性和锁的可靠性,但需要权衡性能和复杂性。在选择时,需要根据具体场景来决定是否使用该种锁机制。