Sentinel 是阿里中间件团队研发的面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
从一次 HTTP 请求开始
在一个生产环境中,服务节点通常暴露了成百上千个 HTTP 接口对外提供服务。为了保证系统的稳定性,核心 HTTP 接口往往需要配置限流规则。给 HTTP 接口配置限流,可以防止突发或恶意的高并发请求耗尽服务器资源(如 CPU、内存、数据库连接等),从而避免服务崩溃或引发雪崩效应。
基础示例
假设我们有下面这样一个 HTTP 接口,需要给它配置限流规则:
使用起来非常简单。首先我们可以选择给接口加上 @SentinelResource 注解(也可以不加,如果不加 Sentinel 客户端会使用请求路径作为资源名,详细原理在后面章节讲解),然后到流控控制台给该资源配置流控规则即可。
限流规则的加载
限流规则的生效,是从限流规则的加载开始的。聚焦到客户端的 RuleLoader 类,可以看到它支持了多种规则的加载:
流控规则;
集群限流规则;
熔断规则;
……
RuleLoader 核心逻辑
RuleLoader 类的核心作用是将这些规则加载到缓存中,方便后续使用:
流控规则加载详情
以流控规则的加载为例深入FlowRuleManager.loadRules 方法可以看到其完整的加载逻辑:
updateValue 方法负责通知所有监听器配置变更:
FlowPropertyListener 是流控规则变更的具体监听器实现:
SentinelServletFilter 过滤器
在 Sentinel 中,所有的资源都对应一个资源名称和一个 Entry。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 API 显式创建。Entry 是限流的入口类,通过 @SentinelResource 注解的限流本质上也是通过 AOP 的方式进行了对 Entry 类的调用。
Entry 的编程范式
Entry 类的标准使用方式如下:
Servlet Filter 拦截逻辑
对于一个 HTTP 资源,在没有显式标注 @SentinelResource 注解的情况下,会有一个 Servlet Filter 类 SentinelServletFilter 统一进行拦截:
SentinelResourceAspect 切面
如果在接口上标注了 @SentinelResource 注解,还会有另外的逻辑处理。Sentinel 定义了一个单独的 AOP 切面 SentinelResourceAspect 专门用于处理注解限流。
SentinelResource 注解定义
先来看看 @SentinelResource 注解的完整定义:
实际使用示例
下面是一个完整的使用示例,展示了 @SentinelResource 注解的各种配置方式:
SentinelResourceAspect 核心逻辑
@SentinelResource 注解由 SentinelResourceAspect 切面处理,核心逻辑如下:
流控处理核心逻辑
从入口函数开始,我们深入到流控处理的核心逻辑。
入口函数调用链
ProcessorSlotChain 功能插槽链
lookProcessChain 方法实际创建了 ProcessorSlotChain 功能插槽链。ProcessorSlotChain 采用责任链模式,将不同的功能(限流、降级、系统保护)组合在一起。
SlotChain 的获取与创建
SlotChain 的构建
SlotChain 的功能划分
Slot Chain 可以分为两部分:
统计数据构建部分(statistic):负责收集各种指标数据;
判断部分(rule checking):根据规则判断是否限流。
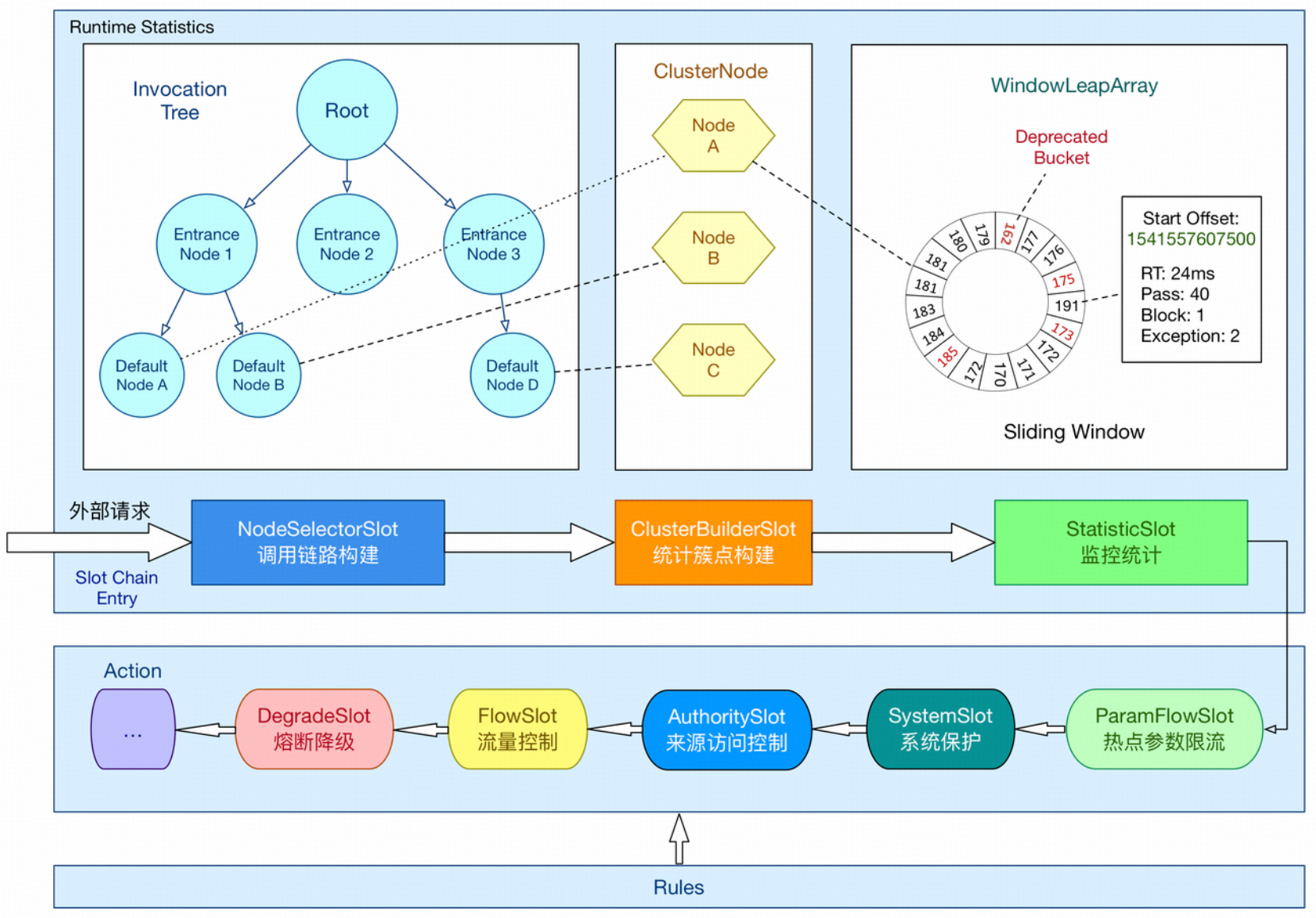 官方架构图很好地解释了各个 Slot 的作用及其负责的部分。目前 ProcessorSlotChain 的设计是一个资源对应一个,构建好后缓存起来,方便下次直接取用。
官方架构图很好地解释了各个 Slot 的作用及其负责的部分。目前 ProcessorSlotChain 的设计是一个资源对应一个,构建好后缓存起来,方便下次直接取用。
各 Slot 的执行顺序
以下是 Sentinel 中各个 Slot 的默认执行顺序:
NodeSelectorSlot - 上下文节点选择
这个功能插槽主要为资源下不同的上下文创建对应的 DefaultNode(实际用于统计指标信息)。解释一下Sentinel中的Node是什么,简单来说就是每个资源统计指标存放的容器,只不过内部由于不同的统计口径(秒级、分钟及)而分别有不同的统计窗口。Node在Sentinel不是单一的结构,而是总体上形成父子关系的树形结构。
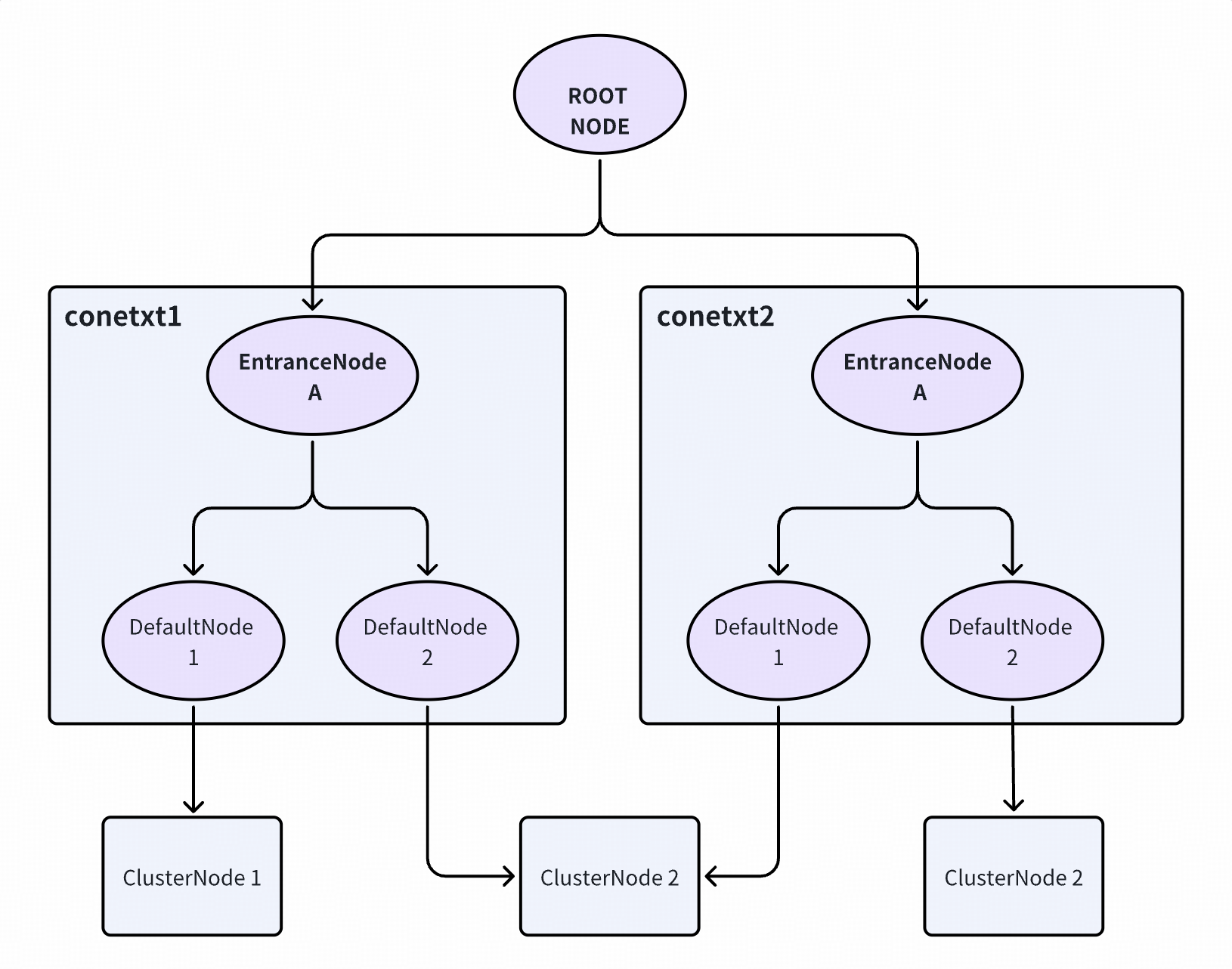 不同的调用会有不同的 context 名称,如在当前 MVC 场景下,上下文为 sentinel_web_servlet_context。
不同的调用会有不同的 context 名称,如在当前 MVC 场景下,上下文为 sentinel_web_servlet_context。
ClusterBuilderSlot - 集群节点构建
这个功能槽主要用于创建 ClusterNode。ClusterNode 和 DefaultNode 的区别是:
DefaultNode 是特定于上下文的(context-specific);
ClusterNode 是不区分上下文的(context-independent),用于统计该资源在所有上下文中的整体数据。
StatisticSlot - 统计插槽
StatisticSlot 是 Sentinel 最重要的类之一,用于根据规则判断结果进行相应的统计操作。
统计逻辑说明
entry 的时候:
依次执行后续的判断 Slot;
每个 Slot 触发流控会抛出异常(BlockException 的子类);
若有 BlockException 抛出,则记录 block 数据;
若无异常抛出则算作可通过(pass),记录 pass 数据。
exit 的时候:
- 若无 error(无论是业务异常还是流控异常),记录 complete(success)以及 RT,线程数 -1。
记录数据的维度:
线程数 +1;
记录当前 DefaultNode 数据;
记录对应的 originNode 数据(若存在 origin);
累计 IN 统计数据(若流量类型为 IN)。
StatisticNode 数据结构
到这里,StatisticSlot 的作用已经比较清晰了。接下来我们需要分析它的统计数据结构。fireEntry 调用向下的节点和之前的方式一样,剩下的节点主要包括:
ParamFlowSlot;
SystemSlot;
AuthoritySlot;
FlowSlot;
DegradeSlot;
其中比较常见的是流控和熔断:FlowSlot、DegradeSlot,所以下面我们着重分析 FlowSlot。
FlowSlot - 流控插槽
这个 Slot 主要根据预设的资源的统计信息,按照固定的次序依次生效。如果一个资源对应两条或者多条流控规则,则会根据如下次序依次检验,直到全部通过或者有一个规则生效为止。
FlowSlot 核心逻辑
checkFlow 方法详解
通过这里我们就可以得知,流控规则是通过 FlowRule 来完成的,数据来源是我们使用的流控控制台,也可以通过代码进行设置。
FlowRule 流控规则
每条流控规则主要由三个要素构成:
**grade(阈值类型):**按 QPS(每秒请求数)还是线程数进行限流;
**strategy(调用关系策略):**基于调用关系的流控策略;
**controlBehavior(流控效果):**当 QPS 超过阈值时的流量整形行为。
滑动窗口算法
不管流控规则采用何种流控算法,在底层都需要有支持指标统计的数据结构作为支撑。在 Sentinel 中,用于支撑基于 QPS 等限流的数据结构是 StatisticNode。
StatisticNode 数据结构
ArrayMetric 核心实现
ArrayMetric 是 Sentinel 中数据采集的核心,内部使用了 BucketLeapArray,即滑动窗口的思想进行数据的采集。
这里有两种实现:
BucketLeapArray:普通滑动窗口,每个时间桶仅记录固定时间窗口内的指标数据;OccupiableBucketLeapArray:扩展实现,支持"抢占"未来时间窗口的令牌或容量,在流量突发时允许借用后续窗口的配额,实现更平滑的限流效果。
BucketLeapArray - 滑动窗口实现
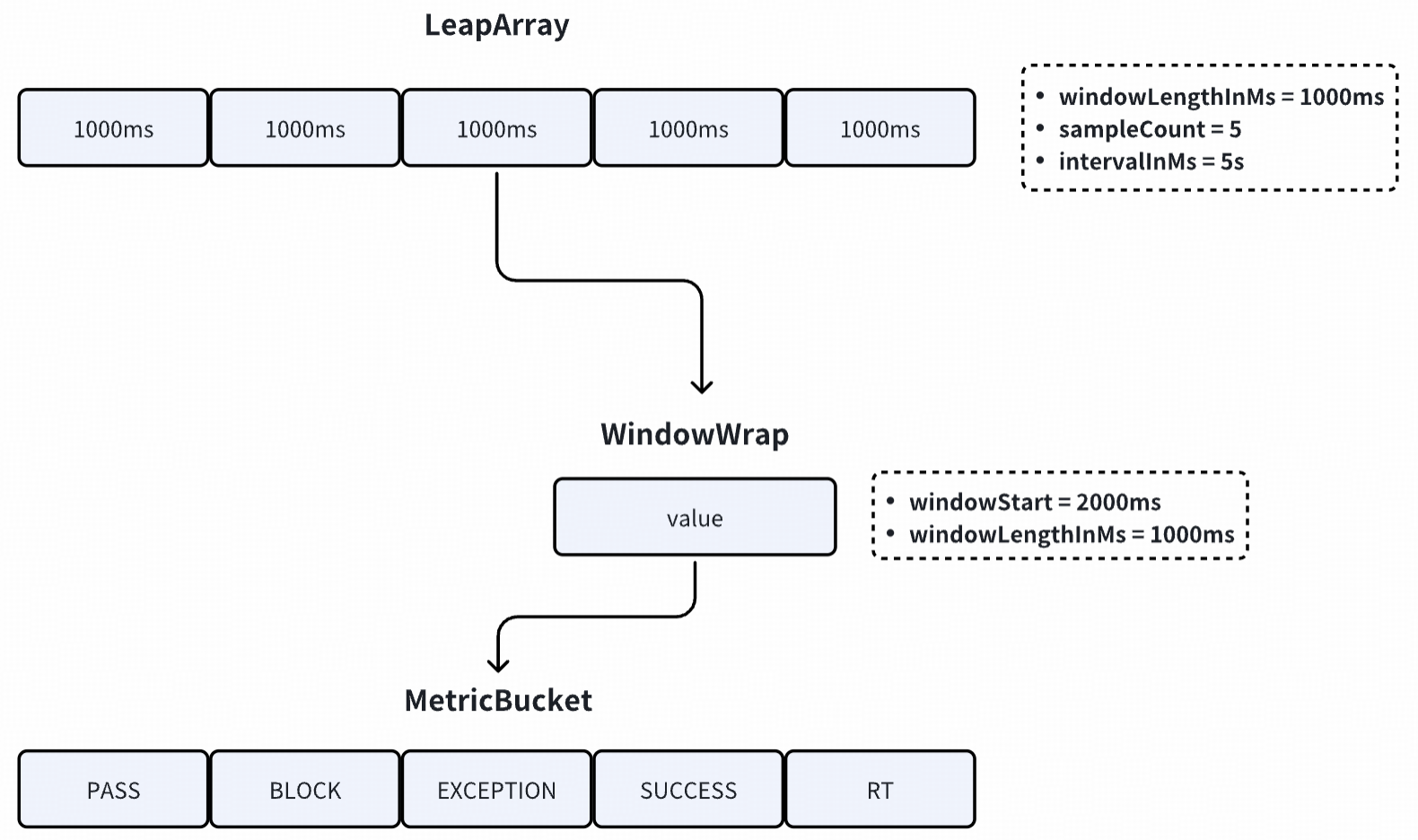
LeapArray 核心属性
Sentinel 中滑动窗口算法的核心类,先了解一下他的核心成员变量
WindowWrap 窗口包装器
每个窗口包装器包含三个属性:
MetricBucket 指标桶
滑动窗口工作原理
LeapArray 统计数据的基本思路:
创建一个长度为 n 的数组,数组元素就是窗口;
每个窗口包装了 1 个指标桶,桶中存放了该窗口时间范围内对应的请求统计数据;
可以想象成一个环形数组在时间轴上向右滚动;
请求到达时,会命中数组中的一个窗口,该请求的数据就会存到命中的这个窗口包含的指标桶中;
当数组转满一圈时,会回到数组的开头;
此时下标为 0 的元素需要重复使用,它里面的窗口数据过期了,需要重置,然后再使用。
获取当前窗口
LeapArray 获取当前时间窗口的方法:
calculateTimeIdx
利用一个数组实现时间轴,每个元素代表一个时间窗口
Sentinel 中 数组长度是固定的,通过方法 calculateTimeIdx 来 确定时间戳在数组 中的位置 (找到时间戳对应的窗口位置)
怎么理解这个方法呢?
把数据带入进去,假设 windowLengthInMs = 500 ms (每个时间窗口大小是 500 ms)
如果 timestamp 从 0 开始的话,每个时间窗口为 [0,500) [500,1000) [1000,1500) …
这时候先不考虑 timeId % array.length(),也不考虑数组长度。假设当前 timeMillis = 601,将数值代入到 timeMillis / windowLengthInMs 其实就可以确定出当前的 timestamp 对应的时间窗口在数组中的位置了
由于数组长度是固定的,所以再加上求余数取模来确定时间窗在数组中的位置
currentWindow
先看下Window 的结构,计数器使用了泛型,可以更灵活
currentWindow方法根据传入的 timestamp 找到 或者 创建 这个时间戳对应的 Window
方法逻辑分析如下:
首先要做的两件事
计算 timestamp 在数组中的位置,就是上文说的 calculateTimeIdx
计算 timestamp 的 windowStart (窗口开始时间),通过 timeMillis - timeMillis % windowLengthInMs
然后进入一个 while(true) 循环, 通过 WindowWrap<T> old = array.get(idx) 找出对应的窗口,接下来就是三种情况了
old == null:这个时候代表数组中还没有这个 window,创建这个 window 加入到数组中(由于此时可能会有多个线程同时添加数组元素,所以一定要保证线程安全,所以这里使用的数组为 AtomicReferenceArray),添加成功后返回新建的 window
windowStart == old.windowStart():window 已经存在了,直接返回即可
windowStart > old.windowStart():代表数组中的元素已经至少是 25s 之前的了,重置当前窗口的 windowStart 和 计数器,这个操作同样也是一个多线程操作,所以使用了 updateLock.tryLock()。
windowStart < old.windowStart():通常情况下不会走到这个逻辑分支
values
上文中提到计算流量时具体使用几个窗口,取决于窗口大小和单位时间大小
该方法的作用通过传入一个时间戳,找出本次计算所需的所有时间窗口
重点看一下 isWindowDeprecated 这个方法
还是像上面那样把数值带进去。每个窗口大小为 500 ms,例如 timestamp 为 1601,这个 timestamp 对应的 windowStart 为 1500,此时 (1601 - 1500 > 1000) = false 即这个窗口是有效的,再往前推算,上一个窗口 windowStart 为 1000 也是有效的。再往前推算,或者向后推算都是无效的窗口。
数据存储
在获取到窗口之后,就可以存储数据了。ArrayMetric 实现了 Metric 中存取数据的接口方法。
示例:存储 RT(响应时间)
数据读取
示例:读取 RT(响应时间)
Sentinel 限流思路
在理解了 LeapArray#currentWindow 和 LeapArray#values 方法的细节之后,其实我们就可以琢磨出限流的实现思路了
首先根据当前时间戳,找到对应的几个 window,根据 所有 window 中的流量总和 + 当前申请的流量数 决定能否通过
如果不能通过,抛出异常
如果能通过,则对应的窗口加上本次通过的流量数
OccupiableBucketLeapArray - 可抢占窗口
为什么需要 OccupiableBucketLeapArray?
假设一个资源的访问 QPS 稳定是 10,请求是均匀分布的:
在时间 0.0-1.0 秒区间中,通过了 10 个请求;
在 1.1 秒的时候,观察到的 QPS 可能只有 5,因为此时第一个时间窗口被重置了,只有第二个时间窗口有值;
当在秒级统计的情形下,用 BucketLeapArray 会有 0~50%的数据误这时就要用 OccupiableBucketLeapArray 来解决这个问题。
OccupiableBucketLeapArray 实现
从上面我们可以看到在秒级统计 rollingCounterInSecond 中,初始化实例时有两种构造参数:
漏斗算法的实现
Sentinel 主要根据 FlowSlot 中的流控进行流量控制,其中 RateLimiterController 就是漏斗算法的实现
整体逻辑如下:
首先计算出当前请求平摊到 1 秒内的时间花费,然后去计算这一次请求预计时间;
如果小于当前时间的话,那么以当前时间为主,返回即可;
反之如果超过当前时间的话,这时候就要进行排队等待了。等待的时候要判断是否超过当前最大的等待时间,超过就直接丢弃;
没有超过就更新上一次的通过时间,然后再比较一次是否超时。如果还超时就重置时间,反之在等待时间范围之内的话就等待。如果都不是,那就可以通过了。
令牌桶算法的实现
Sentinel 的令牌桶实现基于 Guava,代码在 WarmUpController 中。
拿到当前窗口和上一个窗口的 QPS;填充令牌,也就是往桶里丢令牌。
填充令牌的逻辑如下:
拿到当前的时间,然后去掉毫秒数得到的就是秒级时间;
判断时间小于这里就是为了控制每秒丢一次令牌;
然后就是 coolDownTokens 去计算我们的冷启动 / 预热是怎么计算填充令牌的;
后面计算当前剩下的令牌数,这个就不说了。减去上一次消耗的就是桶里剩下的令牌。
最开始的时候因为 lastFilledTime 和 oldValue 都是 0,所以根据当前时间戳会得到一个非常大的数字。最后,和 maxToken 取小的话就得到了最大的令牌数。所以第一次初始化的时候就会生成 maxToken 的令牌;
之后我们假设系统的 QPS 一开始很低,然后突然飙高。所以,开始的时候回一直走到高于警戒线的逻辑里去,然后 passQps 又很低。所以,会一直处于把令牌桶填满的状态(currentTime - lastFilledTime.get() 会一直都是 1000,也就是 1 秒),所以每次都会填充最大 QPScount 数量的令牌;
然后突增流量来了,QPS 瞬间很高。慢慢地令牌数量就会消耗到警戒线之下,走到我们 if 的逻辑里去,然后去按照 count 数量增加令牌。
上面的逻辑理顺之后,我们就可以继续看限流的部分逻辑:
令牌计算的逻辑完成,然后判断是不是超过警戒线。按照上面的说法,低 QPS 的状态肯定是一直超过的,所以会根据斜率来计算出一个 warningQps。因为我们处于冷启动的状态,所以这个阶段就是要根据斜率来计算出一个 QPS 数量,让流量慢慢地达到系统能承受的峰值。举个例子,如果 count 是 100,那么在 QPS 很低的情况下,令牌桶一直处于满状态。但是系统会控制 QPS,实际通过的 QPS 就是 warningQps,根据算法可能只有 10 或者 20(怎么算的不影响理解)。QPS 主键提高的时候,aboveToken 再逐渐变小,整个 warningQps 就在逐渐变大。直到走到警戒线之下,到了 else 逻辑里;
流量突增的情况,就是 else 逻辑里低于警戒线的情况,我们令牌桶在不停地根据 count 去增加令牌。此时消耗令牌的速度超过我们生成令牌的速度,可能就会导致一直处于警戒线之下。这时候判断当然就需要根据最高 QPS 去判断限流了。
所以,按照低 QPS 到突增高 QPS 的流程,来想象一下这个过程:
刚开始,系统的 QPS 非常低,初始化我们就直接把令牌桶塞满了;
然后这个低 QPS 的状态持续了一段时间,因为我们一直会填充最大 QPS 数量的令牌(因为取最小值,所以其实桶里令牌基本不会有变化),所以令牌桶一直处于满的状态,整个系统的限流也处于一个比较低的水平。这以上的部分一直处于警戒线之上。实际上就是叫做冷启动 / 预热的过程;
接着系统的 QPS 突然激增,令牌消耗速度太快。就算我们每次增加最大 QPS 数量的令牌任然无法维持消耗,所以桶里的令牌在不断低减少。这个时候,冷启动阶段的限制 QPS 也在不断地提高,最后直到桶里的令牌低于警戒线;
低于警戒线之后,系统就会按照最高 QPS 去限流,这个过程就是系统在逐渐达到最高限流的过程。那这样一来,实际就达到了我们处理突增流量的目的,整个系统在漫漫地适应突然飙高的 QPS,然后最终达到系统的 QPS 阈值;
最后,如果 QPS 回复正常,那么又会逐渐回到警戒线之上,就回到了最开始的过程。