题⽬描述
请实现两个函数,分别⽤来序列化和反序列化⼆叉树
⼆叉树的序列化是指:把⼀棵⼆叉树按照某种遍历⽅式的结果以某种格式保存为字符串,从⽽使得内存中建⽴起来的⼆叉树可以持久保存。序列化可以基于先序、中序、后序、层序的⼆叉树遍历⽅式来进⾏修改,序列化的结果是⼀个字符串,序列化时通过 某种符号表示空节点( # ),以 ! 表示⼀个结点值的结束( value! )。
⼆叉树的反序列化是指:根据某种遍历顺序得到的序列化字符串结果str,重构⼆叉树。例如,我们可以把⼀个只有根节点为1的⼆叉树序列化为" 1",然后通过⾃⼰的函数来解析回这个⼆叉树
示例1 输⼊:{8,6,10,5,7,9,11} 返回值:{8,6,10,5,7,9,11}
思路及解答
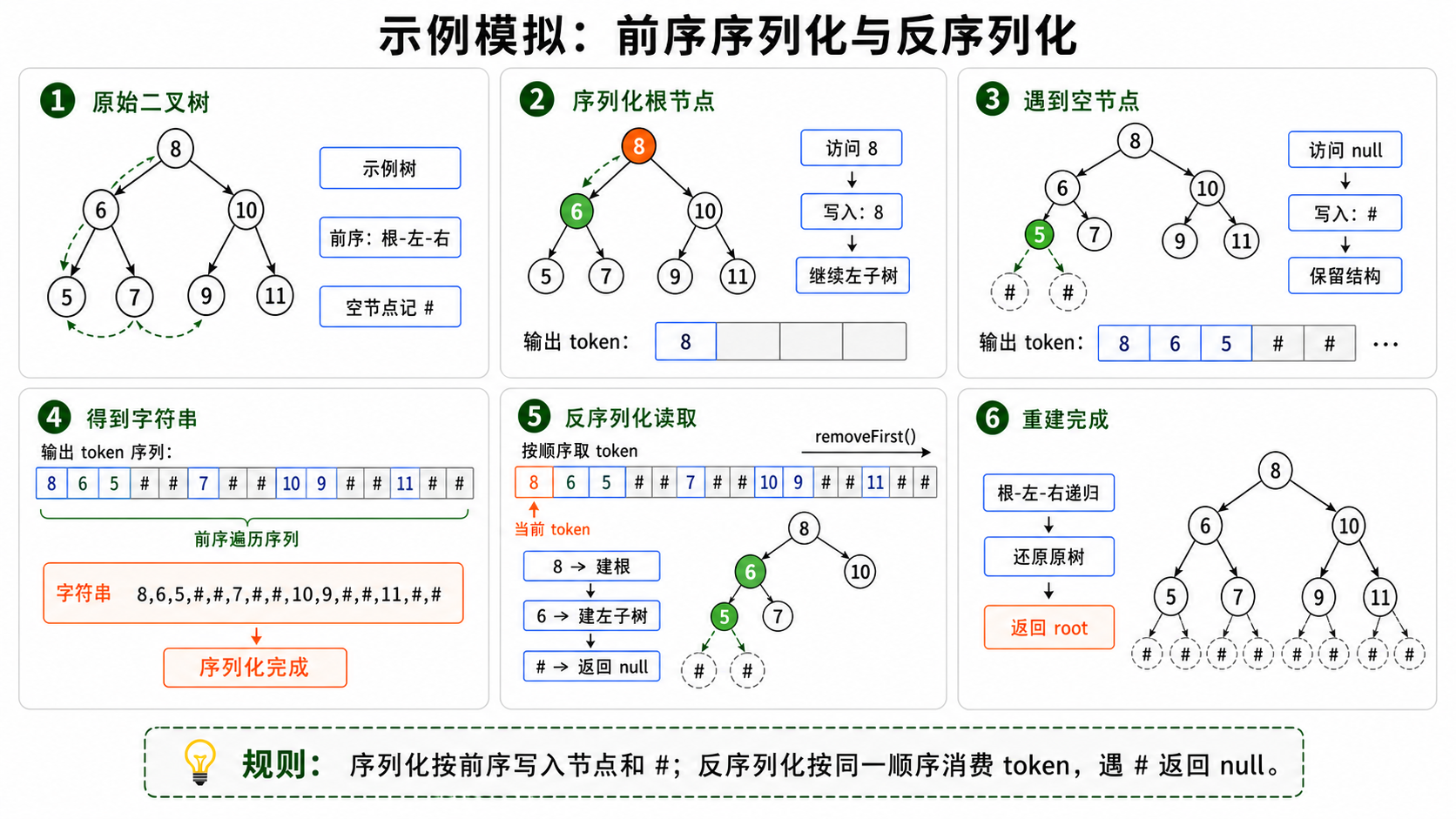
前序遍历(递归)
利用二叉树的前序遍历顺序(根-左-右)进行序列化,并使用特殊字符(如"#“或"null”)表示空节点,以确保树结构的唯一性。
序列化思路:从根节点开始,先输出当前节点的值,然后递归地序列化左子树和右子树。遇到空节点时,输出空标记(如"#")。
反序列化思路:按照前序遍历的顺序,依次从序列化字符串中读取节点值。如果读取到空标记,则返回null;否则,用当前值创建节点,并递归构建其左子树和右子树
时间复杂度:O(n),每个节点恰好被访问一次。
空间复杂度:O(n),递归调用栈的深度在最坏情况下(树退化为链表)为O(n),序列化字符串长度也与节点数n成线性关系。
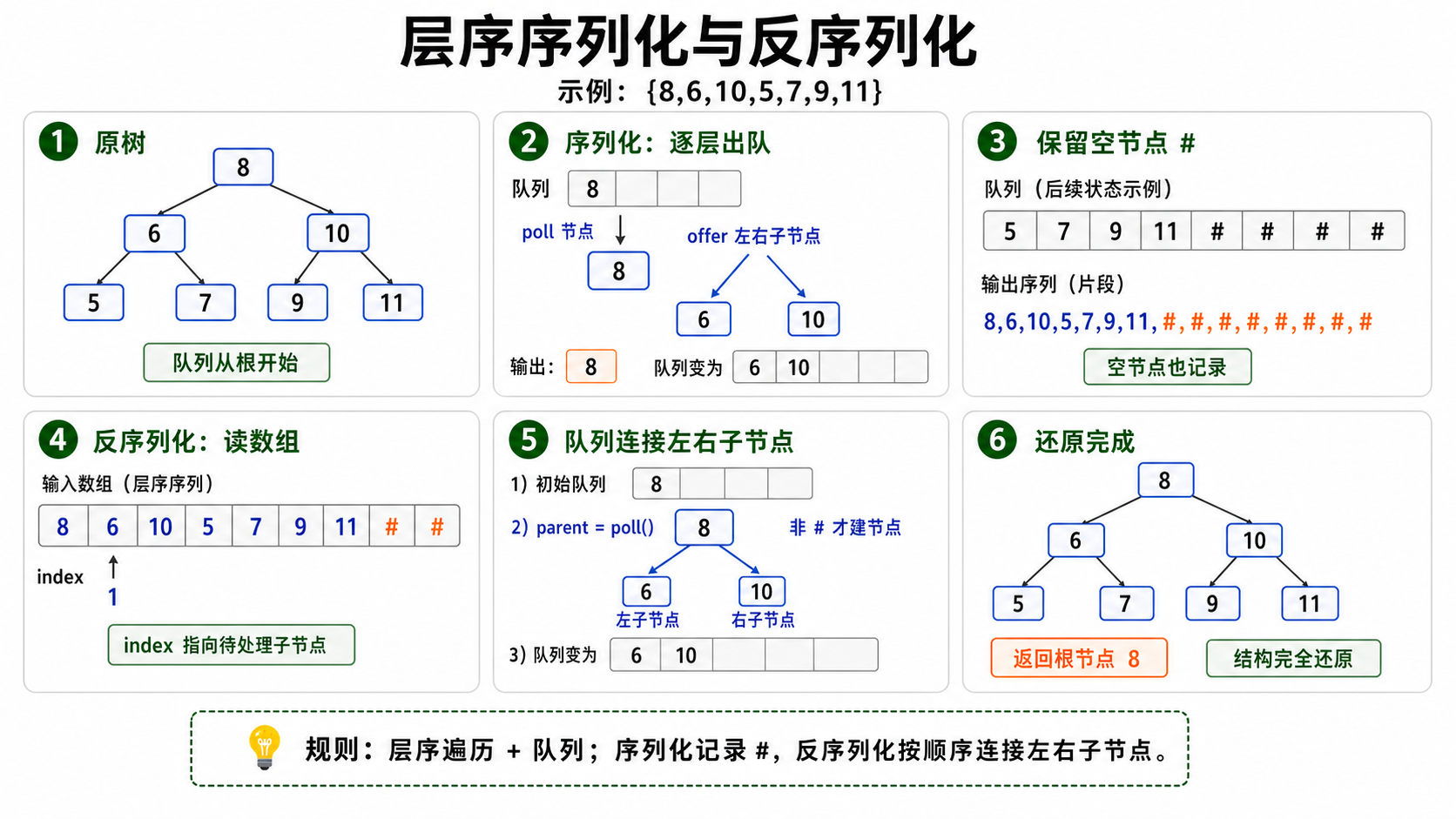
层序遍历(迭代)
层序遍历(广度优先搜索)更直观,可以按层级顺序处理节点,适合处理接近完全二叉树的情况。
序列化思路:使用队列辅助进行层序遍历。从根节点开始,将节点值加入字符串,并将其非空子节点(即使是空节点也记录)加入队列,以确保树结构信息完整。
反序列化思路:同样使用队列,根据序列化字符串的顺序,依次为每个非空节点创建其左右子节点
时间复杂度:O(n),每个节点入队、出队各一次。
空间复杂度:O(n),队列中最多同时存储约n/2个节点(完全二叉树的最后一层)。
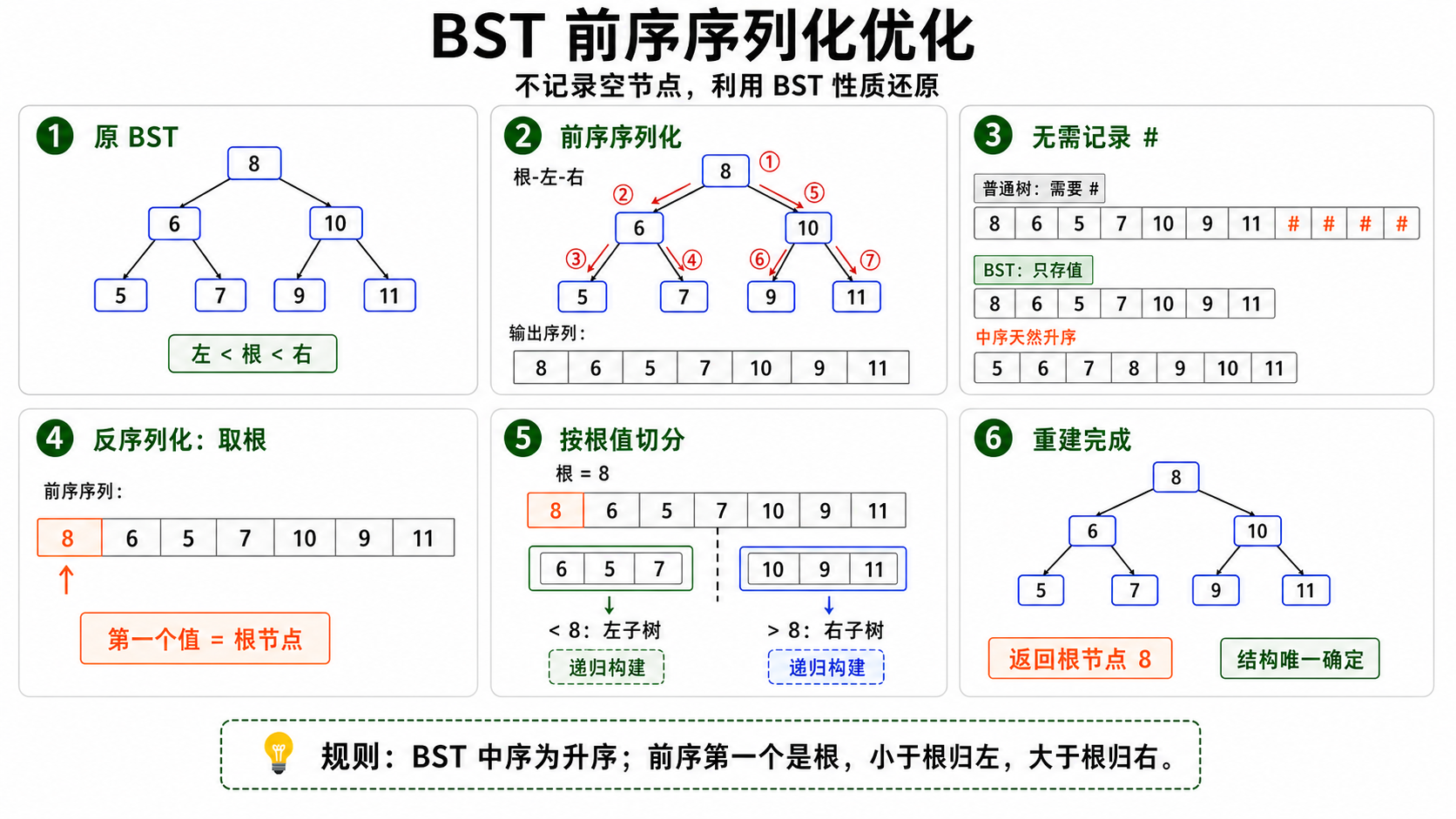
二叉搜索树(BST)前序优化
对于二叉搜索树(BST),可以利用其中序遍历为升序的特性,仅通过前序或后序序列即可唯一确定树结构,无需显式存储空节点。
序列化思路:对BST进行前序遍历,将节点值拼接成字符串。由于BST的性质,中序遍历就是节点值的升序排列,因此仅凭前序遍历结果就能唯一确定树结构。
反序列化思路:根据前序遍历结果,第一个元素为根节点。剩余元素中,所有小于根节点的值构成左子树的前序遍历,大于根节点的值构成右子树的前序遍历。递归进行即可重建BST
时间复杂度:O(n log n) 最坏情况下(BST退化为链表)为O(n²),平均情况下为O(n log n)。这是因为在重建过程中,需要为每个节点在序列中查找其左右子树的分界点。
空间复杂度:O(n),用于存储递归栈和序列化字符串。