如何在附近 100w 的商户中,快速找到离你最近的 5 家商户?
可以使用 MySQL或 MongoDB 的空间索引,或者使用 Redis 提供的 Geo 数据结构来存储商户位置的位置信息来实现根据距离的快速查找
使用空间索引
例如 R-tree,它适用于二维空间的树形数据结构,能够高效地进行范围查询和最近邻查询。将商户位置(经纬度)数据按照地理区域组织成树结构,可以快速找到位于用户当前位置附近
像 MySQL 就支持 R-tree,或者使用 MongoDB 也支持空间索引。
拿 MongoDB 举例,实现步骤就是
创建一个地理集合
将商家的经纬度导入到集合中
创建地理索引:给location 创建 2dsphere 索引
根据自己的坐标,利用 $near查询附近距离
这里已经自动按最近的排序了,再结合.1imit(20)即可得到最近的 20家饭店。
使用 Redis 的 Geospatial
Redis 内部使用 Geohash 算法将地理坐标编码为字符串的技术,通过将地球表面划分成网格,来减少坐标的存储空间,并目能够根据前缀进行范围搜索实现快速的区域范围搜索
数据存储: 使用 Redis 的 GEOADD命令,将饭店的地理位置信息存储在 Redis 中。每个饭店的经纬度信息作为空间坐标进行存储,并关联到饭店的唯一标识符。
查询附近的饭店: 使用 GEORADIUS 命令,根据用户当前位置(经纬度)查询指定半径内的饭店,并按距离排序,返回最接近的 20 家饭店
user longitude 和 user latitude 是用户的经纬度。
radius 是查询的半径,单位可以是 m(米)、km(千米)等。
WITHDISTANCE 返回与用户的距离。
COUNT 20 ASC 返回距离最近的前 20 个结果,并按距离升序排列。
线上数据库连接池爆满问题排查
如果出现了线上连接池爆满的情况,一般情况需要先“止损”,也就是重启服务。
现在一般都会用云上的服务,会有监控,对应监控能查到历史数据库的情况,包括连接池的占用情况、重启后我们快速分析定位事故反生之前一段时间 SOL的执行情况,连接池的占用情况。
查看当时是否有大量的突发清求,例如做了运营活动,那么很可能请求数上来会导致数据车压力过大,处理缓慢使得连接池占用久导致连接数满了。这种情况应该之前预先压测,并且通过限流等手段控制服务的整体压力,。
查看是否有慢 SOL导致长时间连接的占用,需要特别注意近期上线的功能,快速定位查找可能影响的功能点进行代码修复。
查看连接池配置是否合理,大部分默认的连接池的最大连接数可能就只有8或者 10,这种情况下需要适当提高最大连接数,具体连接数需要根据具体业务压测后配置
常见数据库查询性能优化
查看慢查询日志:分析数据库慢查询日志,查看是否有查询性能较差的SQL语句,导致连接长期占用。
优化查询:对于慢查询,可以优化 SOL、增加索引、减少全表扫描等,提升查询效率,减少数据库连接的占用时间。
数据库锁竞争:确认是否有长时间持有锁的 SOL查询,避免长时间的锁竞争导致连接池中的连接无法释放。
面对突发流量应对措施
限流:限制每秒请求的数量,避免瞬时流量过大导致连接池耗尽。
请求排队:通过消息队列等将请求异步化,减轻数据库直接访问的压力。可以将需要访问数据库的操作转到后台处理,而不是即时返回。(业务上需要做开关,开关打开后就异步处理,正常情况下同步处理)
服务降级:对于某些非核心功能,考虑返回默认值或缓存数据,避免直接查询数据库,减轻高峰期的压力
项目上现在需要存储IP 地址,数据库应该用什么类型来存储?
面试时核心要回答清楚两点:IPv4和IPv6的最优存储类型,以及为什么选这个类型
Mysql
IPv4:优先用无符号整型 (如MySQL的INT UNSIGNED),而不是字符串(如VARCHAR)。
IPv6:优先用二进制类型(如BINARY(16)或VARBINARY(16)),次选定长字符串(如CHAR(39))。
为什么IPv4不用字符串?
IP地址(如 192.168.1.1)本质是32位二进制数(4字节),用字符串存会浪费空间。
字符串存储:需要15字节(如255.255.255.255),且查询时逐字符比较,效率低
整型存储:4字节(无符号整型范围0~4294967295,刚好覆盖 IPv4所有可能地址,比较时直接按数值比,更快。还能节省数据库存储空间和IO开销。
举个例子:MySQL有两个函数 INET_ATON()(IP转整型) 和 INET_NTOA()(整型转IP),可以轻松转换。
IPv6为什么用二进制?
IPv6地址是128位(16字节),用字符串存储需要39字节(如2801:0080:1F1F:0888:888:0108:11A8:0F),而二进制类型 BINARY(16) 仅需16字节,空间节省一半以上。
部分数据库(如MySQL)也支持 INET6_ATON() 和 INET6_NTOA() 函数转换IPv6,但二进制存储更高效。
反正,面试时要强调“整型/二进制比字符串更省空间、查询更快”,再能说出具体的数据库函数(如INETATON) 或 专用类型(如PostareSQL的inet),体现对底层原理的理解!
PostgreSQl
如果用 PostgreSQl,可以直接用 inet 类型(支持IPV4和IPV6),它会自动验证 iP 格式,且查询时支持范围判断(如 WHERE ip>“192.168.1.0’),更方便
IPv4 转 int 类型转换原理和流程(以 MySQL 为例)
转换原理
IPv4地址(如 192.168.1.1)是4个8位二进制数(0-255)的点分形式,本质是32位无符号整数(范围:0~4294967295)
转换过程:将每个段(如192、168、1、1)按位拼接成一个32位整数。例如:192.168.1.1=192x256^3+168 x 256^2 +1x256^1+ 1 x 256^0 =3232235777
插入和查询流程
步骤1:创建表(字段类型为INT UNSIGNED)
步骤2:插入数据(用INET ATON()转整型
MySQL提供 INET_ATON(ip_str)函数,直接将IPv4字符串转为整型
步骤3:查询数据(用INET NTOA()转回字符串
查询时用 INET_NTOA(int_ip)函数,将整型转回点分格式,
IPv6 转二进制类型转换原理和流程(以 MySQL为例)
转换原理
IPv6地址(如 2001:0000:1F1F:0000:0000:0100:11A0:ADDF)是128位二进制数(16字节),用字符串存储需39字节,而二进制仅需16字节
转换过程:将IPv6的16进制字符串(冒号分隔)转为16字节的二进制数据。
插入和查询流程
步骤1:创建表(字段类型为BINARY(16))
步骤2:插入数据(用INET6_ATON()转二进制)
MySQL的 INET6 ATON(ipv6_str)函数可将IPv6字符串转为16字节的二进制数据
步骤3:查询数据(用INET6_NTOA()转回字符串)
查询时用 用INET6_NTOA(binary_ip)函数,将二进制数据转回IPv6字符串:
为什么 IPv6 不能像 IPv4 那样用整数?
核心原因:IPv6 的 128 位长度,超出了主流数据库整数类型的范围,拆成多个整数段又比较复杂和麻烦
IPv4是32位二讲制数(4字节),主流教居库的 无符号整型(QIMSOLINTUNSIGNED) 刚好能存下(4字节=32位,范围0~4294967295),但IPv6是128位(16字节),而主流数居库的整数类型最大只有64位。
MySQL的 BIGINT UNSIGNED是8字节(64位),只能存到18446744873789551615,远小于IPv6的3.4x10^38(128位最大值)。PostgreSQL的 BIGINT 同样是64位,无法存128位的IPv6地址
如果非要用整数存IPv6,需要拆分成多个整数段(比如用2个64位整数拼128位),但会带来3个问题:
存储复杂:需要额外字段(如 high_bits 和 low_bits ),增加表结构复杂度。
查询低效:查询时需要同时比较两个字段(如 WHERE high_bits= … AND low_bits=… ),比直接比较二进制字段慢。
无原生函数支持:主流数据库没有直接操作128位整数的函数(如MySQL的 INET6_ATON 返回的是二进制,不是整数),转换逻辑需要手动写,容易出错。
为什么 IPv4 优先选整型而非二进制?
IPv4 用整型存储更符合其数值本质,且数据库内置函数和查询操作的便捷性远超二进制。
二进制(如BINARY(4))虽然也能存4字节,但它是“字节序列”,需要额外理解其代表的数值含义,还需要多一步手动转换成二进制的步骤,比较麻烦。
项目中同样的功能,可能是环境或其他要求原因,需要适配多种数据库,如何实现?
本质是因为不同数据库 SQL语法、分页、时间函数等细节可能都不一样,所以需要适配
这个问题的核心思路是:抽象数据库访问层,统一接口、隐藏具体实现,再根据配置注入不同的数据源或 SQL 逻辑。
常见方式可以是 ORM (JPA +Hibernate)+方言机制。或者使用 MyBatis+动态 SQL/自定义 Mapper,或自行实现多数据源配置切换
使用 ORM 框架 + 方言机制
比如JPA/Hibernate、MyBatis Plus、Spring Data,都支持数据库方言(Dialect)
改起来其实很简单,ORM 层用统一的 API(如 findById()、分页等,然后底层会通过方言,自动转换成对应数据库的 SQL 语法
自行封装数据库操作
定义统一接口,不同数据库写各自的实现类,运行时根据配置或环境自动选择
然后通过 Spring 的@ConditionalOnProperty或工厂模式动态选择实现:
手写 SQL
使用 MyBatis+动态 SQL/自定义 Mapper
因为 MyBatis 本身不依赖具体数据库,支持不同数据库写不同的 Mapper XML
指定数据库类型
20亿手机号存储选int还是string?varchar还是char?为什么?
- int存得下11位数字嘛?
首先,我们都知道手机号,是11位的数字,比如13728199213.
在Java中,int是 32位,最大值为 2^31 - 1 = 2,147,483,647。约等于 2×10⁹。显然,如果用int,根本存不下 11位的手机号码。
要想存的下,得用64位的Long类型,也就是对应数据库的bigInt。
- 数据完整性
例如手机号01324567890,用Long存会变成1324567890,直接破坏数据完整性。
并且,有时候,有些手机号可能包含国家代码如(+86),或者有些时候,是有连字符的,比如137-2819-9213. 这些原因都导致不能用整型类型存储。
- 查询麻烦
比如,你要查找,手机号是137开头的手机号号码,如果用BigInt(Long类型)需先转字符串再模糊匹配,效率暴跌。
- 用String有哪些好处
保真:数字、符号、前导零全能存,原样保留。
灵活:支持模糊查询、国际号码,扩展无忧。
省心:无需担心溢出或格式转换问题。
- 为什么用 VARCHAR(20) 而不是 VARCHAR(11)
我们就拿手机号来说,为什么更建议用 VARCHAR(20),而不是VARCHAR(11)呢?
因为我们都知道,手机号是11位的,为什么不直接用VARCHAR(11)呢?
如果你日常开发中,就有思考数据容错性习惯的话,就会想到:
如果遇到国际号码:+8613822223333(14位)
带国家码的号码:008613822223333(15位)
分机号:13822223333#123(超11位)
这些场景,都会导致VARCHAR(11)报错崩盘。
其次就是业务扩展性思考:VARCHAR(11)只能存纯11位数字,假设未来业务需要:
支持座机号(如010-62223333,含横杠)
支持虚拟号(如17012341234-5678)
支持其他登录方式(如邮箱+手机号混合存储)
因此,字段长度和类型需提前为业务变化留余地,避免频繁改表。这就是日常开发中的,业务扩展性思维思考。
还有数据容错性思考,
输入不可控性:用户可能输入带空格/符号的号码(如138 2222 3333),直接存原始值更方便清洗。
设计妥协:若强制用VARCHAR(11),需在代码层严格过滤非数字字符,增加复杂度。
还有思考问题全面性,比如存储成本思考。
VARCHAR(11):最大占 11字节(utf8mb4下1字符占4字节,但数字和+号只占1字节)
VARCHAR(20):最大占 20字节
20亿数据相差仅约 18GB(和用BIGINT的16GB对比,总成本仍可接受)。
所以面试官期待的答案公式:合理长度 = 基础需求 + 国际扩展 + 容错缓冲
当然,这个不是固定答案,主要还是面试的时候,你回答面试官的思路和表达,最好体现你有这几个方面的思考:业务扩展性、数据容错性、思考问题全面性
怎么设计电商系统的订单数据同步方案(同步到数仓)? 要求数据准确、性能高
可以采用 基于事务日志的增量同步(如CDC)+ 消息队列 +下游服务幂等处理 的方案主要链路架构是:订单主库(如MySQL) → Canal监听订单 Binlog 捕获增删改全变更 → 消息队列(Kafka/RocketMQ)缓冲 → 同步服务异步消费 → 数
仓具体来说,重点有三:
数据抓取:用 Canal 对订单数据库的 Binlog 进行监听和解析。这样能避免在业务代码中耦合,保证数据抓取的准确性和高性能,对主库几乎无压力。
数据传输:通过消息队列进行异步解耦。将解析后的订单变更事件发送到MQ(如Kafka/RocketMO)。这能消峰填谷,保证系统吞吐量,并实现生产者和消费者的解耦
数据消费:下游服务必须实现幂等性。由于网络问题可能导致消息重复,需要通过唯一订单ID或业务流水号来保证重复消息不会导致数据错乱.
为了保证数据的准确性,除了幂等消费外,还需要:
定期全量核对主库与数仓,补漏未捕获的事件
每天跑批对比主库与数仓的关键指标(订单总数、总金额),确保一致
为了提升性能:
同步服务从 Kafka 拉批量事件,批量写入数仓,减少 IO 次数。批量处理,
并行消费,按订单ID哈希分区Kafka消息,多实例并行处理,提升吞吐量
设计一个实时数据同步系统,将 MySQL数据实时同步到数据仓库?
设计 MySQL 实时同步到数仓的系统,关键是用 CDC抓变更、靠队列缓冲、按分层处理、保准确提性能
变更捕获:用CDC工具(比如Debezium/Canal)监听MySQL的Binlog,实时抓取增/删/改的全量变更
异步缓冲:把CDC的事件扔到消息队列(比如Kafka),这样扛住大促的流量洪峰,避免同步服务被压垮
同步处理:写个同步服务(用Flink/sparkstreamning或者自研),从队列拉事件,做清洗(过滤无效数据、补全缺失字段)、转换(格式统一,如时间戳转日期)、关联维度(如订单表关联用户信息),再写入数仓。
数仓适配:数仓按 ODS-DWD→DWS、 分层,ODS 存原始变更事件,DWD 洗成干净的明细(比如补全商品类目),DWS 聚合成报表指标(比如每日订单量)
准确和性能:
准确:用唯一标识做幂等(避免重复处理),每天离线对账补
性能:批量写数仓、多实例并行消费、按唯一标识分区分片
如何设计一个高可用的数据同步系统?需要考虑哪些容错机制?
我会用 log-based CDC(如Canal、Debezium)把变更写入 Kafka,在 Kafka 配置副本与 ISR 保证可用性,消费者逻辑做幂等处理并保存消费位点。
遇到写失败靠重试+ DLQ(死信队列)+ 手动回溯来容错。
主要的容错机制:
幂等消费,保证重试的正确性
Kafka 多副本部署,保证消息持久化
失败重试 + 死信队列,保证消息不丢失
保存消费点位(同步数据的点位)
如何实现数据库的不停服迁移?
迁移想着很简单,不就是把一个库的数据迁移到另一个库吗?
但是实际上有很多细节,在面试中我们可以假装思考下,然后向面试官复述以下几点:
首先关注量级,如果是几十万的数据其实直接用代码迁移,简单核对下就结束了。如果数据量大那么才需要好好设计方案。
不停服数据迁移需要考虑在线数据的插入和修改,保证数据的一致性。
迁移还需要注意回滚,因为一旦发生问题需要及时切换回老库,防止对业务产生影响。
双写方案
大部分数据库迁移都会采用双写方案,例如自建的数据库要迁移到云上的数据库这个场景,双写就是同时写入自建的数据库和云上的数据库。我们来过一遍迁移流程:
将云上数据库(新库)作为自建数据库(旧库)的从库,进行数据同步(或者可以利用云上的能力,比如阿里云的 DTS)。
改造业务代码,数据写入修改不仅要写入旧库,同时也要写入新库,这就是所谓的双写,注意这个双写需要加开关,即通过修改配置实时打开双写和关闭双写。
在业务低峰期,确保数据同步完全一致的时候(即主从不延迟,这个都是有对应的监控的),关闭同步,同时打开双写开关,此时业务代码读取的还是旧数据库
进行数据核对,数据量很大的场景只能抽样调查(可以利用定时任务写代码进行抽样核对,一旦不一致就告警和记录。)
如果确认数据一致,此时可以进行灰度切流,比如1%的用户切到读新的数据库,如果发现设问题,则可以逐步增加开放的比例
继续保留双写,跑个几天(或者更久),确保新库确实没问题了,此时关闭双写,只写新库,这时候迁移就完成了。
flink-cdc 方案
除了主从同步,代码双写的方案,也可以采用第三方工具。例效 finkcdc等工具来进行数据的同步,它的优点方便,且支持异构(比如 mysql 同步到 pg、es 等等)的数据源。
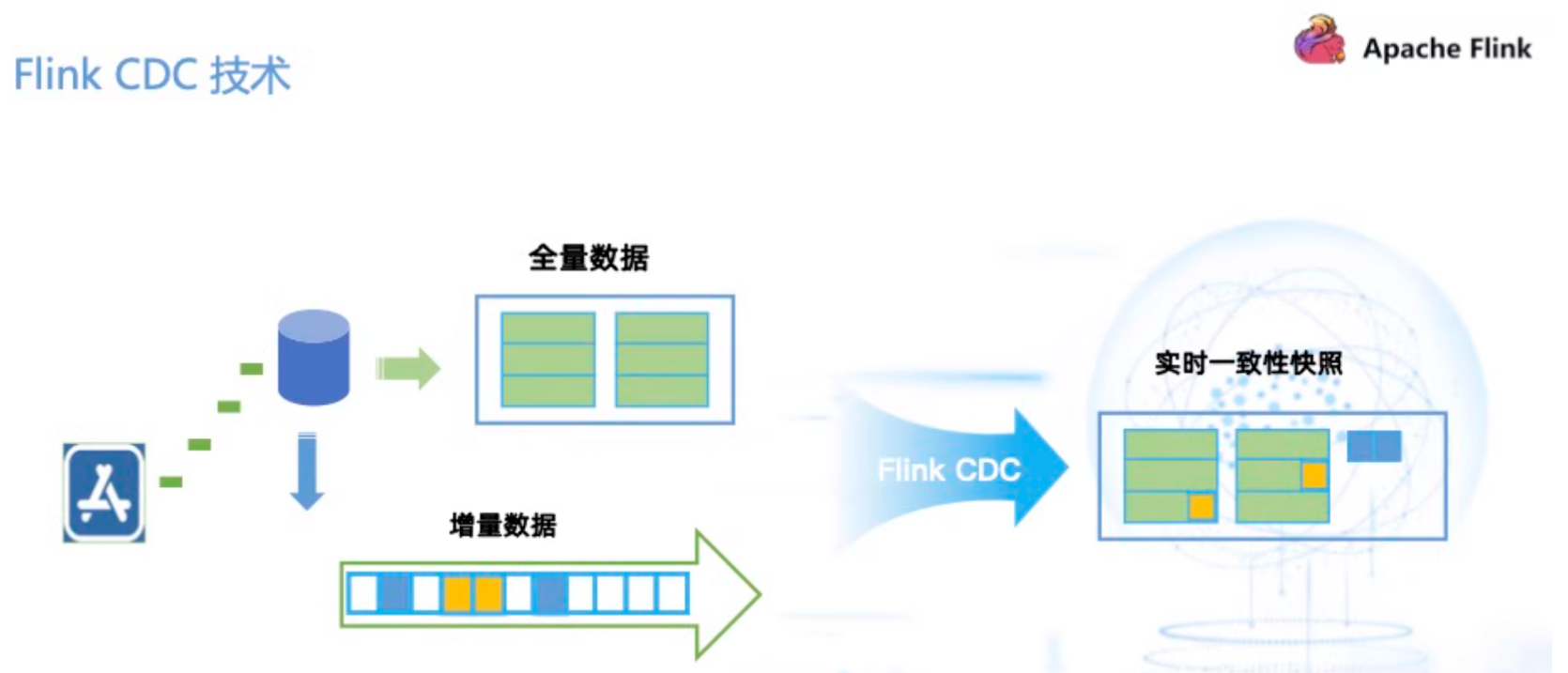 像 fink-cdc 支持先同步全量历史数据,再无缝切到同步增量教据、上图中蓝色小块就是新增的插入数据,会追加到实时一致件快照中;上图中黄色小块是更新的数据,则会在已有历史数据里做更新。
像 fink-cdc 支持先同步全量历史数据,再无缝切到同步增量教据、上图中蓝色小块就是新增的插入数据,会追加到实时一致件快照中;上图中黄色小块是更新的数据,则会在已有历史数据里做更新。
为什么不推荐在 MySQL 中直接存储图片、音频、视频等大容量内容?
MSQL是关系型数据库,它设计的初衷是高效处理结构化和关系型数据,所以存储大容量的内容本身就不是它的职责所在,因此这方面的能力也不够。
应该将大容量文件存储在文件系统或云服务提供的对象存储服务中,仅在数据库中存储文件的路径或 URL即可。
数据库表上新增一个字段,如果这个表正在进行读写操作,如何处理才能不影响现有读写操作?
可以通过 在线DDL操作 或 影子表迁移 来实现。
现在很多数据库都内置在线DDL机制,如MySQL5.6+的 ALGORITHM = INPLACE/ALGORITHM=INSTANT
如果数据库不支持在线 DDL机制,也可以采用应用双写+影子表切换的策略。
主要流程是:先在后台创建新结构的影子表并同步数据,然后在低峰期通过短暂切换(重命名表)完成字段添加,这个过程会短暂的锁表,线上读写基本不受影。可以使用数据同步工具,比如pt-online-schema-chanag、gh-ost来操作。
实际上现在很多云数据库都支持 DDL无锁变更,直接使用即可。
为什么直接加字段会受影响?
比如在 MySQL 5.5 以前版本中执行:
这操作的底层流程是:
创建一个新的临时表结构
把旧表数据一条条复制到新表
删除旧日表
重命名新表
整一个过程都是锁表操作的,此时的读写都会卡住。
所以 MySQL从 5.6 开始支持 Online DDL,就是引入了 ALGORITHM=INPLACE 这样的执行策略。简而言之,它告诉 MySQL:“别动老表的数据,不要复制整张表,在原地修改结构。
例如:
含义是:
INPLACE:尽量“原地”修改表结构,不复制数据
LOCK=NONE:尽量不阻塞任何读写操作(只在开始和结束时加一小会元数据锁)
在 MySQL8.0.12 之后,某些简单变更可以使用 ALGORITHM-INSTANT,只改元数据,不改一行数据,几乎是秒级完成! 适用于:
新增字段必须是 NULL 或者有默认值
没有 NOT NULL 强约束
字段位置必须是最后一个
使用 LIMIT OFFSET 进行分页同步时,发现数据丢失了,可能是什么原因?如何解决?
用 LIMIT OFFSET分页同步丢数据,核心原因是偏移量依赖历史位置,一旦发生数据变动就错乱了。因为 OFFSET N 的本质是先扫描前N条,再跳过它们。
若同步过程中前 N 条数据被删除,后续数据的相对位置会前移,导致实际取到的数据不是预期的下一批。比如原第 11 条因前面删了5条变成第6条,OFFSET 10 会跳过它,直接取第11条,导致漏数据。除此之外,若用 name、create time 等非唯一字段排序,相同排序值的记录顺序不稳定,可能导致某条数据被“跳过”或“重复”
解决方法:
- 优先用游标分页:
不用 OFFSET,而是基于上一页最后一条记录的唯一标识 (如自增ID、时间戳+ID)定位下一页。例如
- 第一页:SELECT* FROM table ORDER BY id ASC LIMIT 10,拿到最后一条id=10
- 第二页:SELECT* FROM table WHERE id>10 ORDER BY id ASC LIMIT 10 。
游标直接定位“具体值”,完全不受中间数据变动影响。
除此之外,不用全量分页,而是就基于日志的增量同步,只同步“变化的数据””,则可以避免分页的偏移问题。
- 约束排序字段唯一性
排序必须用唯一键组合(如id或create time +id),避免因排序字段重复导致游标不稳定。
有一张事件表里面有三个字段,分别是(id,开始时间,结束时间),表中数据量为 5000W,如何统计流量最大的时候有多少条数据?
题干没有告知峰值的统计单位,可以直接询问面试官,原理都是一样的。本答案以秒作为单位,统计每秒的最大值,
我们要统计每秒钟内的最大并发流量,也就是在某一秒内有多少个事件处于活动状态(即时间段的重叠),可以使用差分数组和扫描线思想来实现。
我们可以通过将每个事件活动的开始时间和结束时间记录为增量(开始时流量 +1,结束时流量-1),并通过扫描线的方式对每一秒进行叠加,最终得到每秒的并发流量
假设 start_time 和 end_time 记录的时间单位就是秒,使用一个差分数组(增量数组)来记录每秒的流量变化。
具体来说:我们将每个事件的开始和结束时间处理成时间点(例如:start_time 对应 +1增加并发,end_time +1对应 -1 减少并发),并存储在一个列表中,然后我们对这些时间点进行排序,并计算每个时间点的并发变化,最终找出最大并发数
假设我们有两个事件: 事件1:从2024-12-05 10:00:00 到 2024-12-05 10:00:30 事件2:从2024-12-0510:00:01 到 2024-12-05 10:00:50
我们关心的是这些事件在某些时间点的重叠情况(即并发数),记录每个事件的开始和结束时刻,增减并发数。
时间戳变化图
代码实现如下:
理解上面的思路后,我们再来看看题干,表中有 5000w 数据,所以需要性能优化,而不是一次性加载所有的数据到内存中。
性能优化
对于 5000万条数据的规模,直接查询和处理可能会非常慢。为了提高效率,可以考虑以下优化
索引:在 start_time 和 end_time 字段上创建索引,以加速查询。
按时间范围查询:如果事件按时间分布较均匀,按时间范围(例如每天)分批次查询会更高效。
数据据分批加载:除了时间范围,也可以分页加载处理
减少内存占用:利用 Map 来存储每个时间戳的增减信息,而不需要一次性存储所有时间点。
多线程优化:可以使用多线程并行处理。
代码的改造如下:
分页查询数据库,避免一次性加载所有数据,减少内存压力
使用 parallelStream() 来并行处理每批数据,充分利用多核 CPU 提高性能
ConcurrentSkipListMap 保证线程安全和数据的有序性
类似问题:怎么求出一天 内的最大在线人数?以及维持最大在线人数的最长持续时间?
现在有一天内的大量日志,每条日志记录了用户id,登陆时间,登出时间(userid,login time,logout time;,时间单位是秒。怎么求出一天 内的最大在线人数?以及维持最大在线人数的最长持续时间?
将所有登录时间视为+1 事件,登出时间视为-1事件,放入一个时间线中排序,再依次扫描整个时间轴,记录当前在线人数的变化,即可求出最大在线人数及其持续的最长时间段。 这个方法的时间复杂度为 O(NloqN)。(这叫扫描线算法,这题本质是一个经典的区间重叠统计问题。)
MySQL 中 如果 select from 一个有 1000 万行的表,内存会飙升么?
内存不会飙升。
因为MSQL 在执行简单SELECT * FROM查询时,不会一次性将所有1000万行数据加载到内存中,而是通过逐批次处理的方式来控制内存使用。也就是说 MySQL 是边查边发送数据给客户端, 分批的大小与 net_buffer length 有关,默认16384字节(16 KB)。
所以实际上获取数据和发送数据的流程是这样的:
获取一行,写入到 net_buffer 中。
重复获取行,直到 net_buffer 写满,调用网络接口发出去。
发送成功后 清空 net_buffer 。
再继续取下一行,并写入 net_buffer,继续上述的操作。
这里还需要注意一点,发送的数据是需要被客户端读取的,如果客户端读取的慢,导致本地网络栈(socketsend bufer)写满了,那么当前数据的写入会被暂停。 综上,SELECT * FROM一个有1000 万行的表,不会导致内存飙升。
注意 ORDER BY 和 GROUP BY
正常不需要排序和分组的查询不会占用过多的内存和影响 MySQLServer 的执行,但是如果涉及到分组和排序,那么就需要使用额外的内存(或外部空间)来处理全量数据,可能会占用额外的内存并影响查询的效率。
客户端的处理方式
虽然 MVSQL会分批返回数据,但是客户端需要做一定的处理,不能全量保存教据,否则可能会导致内存溢出。
客户端需要使用流式处理或者游标来查询。
在编写查询代码时,使用流式读取方式(如JDBC中的 ResultSet.FETCH_SIZE),这会让数据库逐步返回数据,客户端按需处理。
MyBatis 简单示例,重点就是 session.getconfiguration().setDefaultFetchsize(Integer.MIN_VALUE);
MyBatis 游标查询示例,重点就是使用cursor接口