工具
LLM 是如何学会调用外部工具的?
模型怎么被训练出工具调用能力,以及训练好之后运行时是怎么工作的。
训练层面靠两个阶段:
SFT(监督微调,Supervised Fine-Tuning):给模型喂大量「工具调用示范对话」,让它通过模仿学会「看到工具描述 -> 判断要不要调 -> 输出结构化 JSON 请求」这整套流程;
RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedback):收集人类对「哪种回答更好」的判断,训练一个打分器,再用这个分数反复调整模型,让它学会什么时候不应该调工具。
运行层面,每次请求时,你的应用代码把工具描述(叫 schema,可以理解为工具的说明书)传给模型,模型如果判断需要工具,就输出一段结构化的 tool_calls JSON;你的代码拿到这段 JSON 去真正执行,把结果塞回对话,模型再给出最终答案。
有一点非常关键:模型全程只是在下指令,真正执行工具的是你的代码,不是模型本身。这套模型决策、代码执行的运行时机制,就是我们常说的 Function Calling。
Agent 如何进行动态 API 调用?
在面对让 LLM Agent 动态调用外部 API 的需求时,核心思路就是让模型能够像调用本地函数一样,把各种 API 当作“工具”提供给它,然后根据用户的意图自动选择并执行对应的工具,
插件机制:先在平台(如 OpenAl Plugin 或 LangChain Agents)中注册好各类 API,把它们封装成插件或工具,当模型检测到用户需要某项功能时,就会自动加载对应插件并发起调用。
动态函数调用:利用 OpenAI GPT-4 Turbo的function calling能力,事先定义好函数接口(函数名、参数格式、返回值结构等),模型在生成响应时如果判断需要调用,就会输出符合该接口的 JSON,并由后端框架解折后触发真实 API 调用。
代码解释器:部署一个受限的Python运行环境(或沙箱),当模型需要做一些计算、数据处理甚至调用第三方库时,会生成相应的代码片段,在该环境中执行后再将结果反馈给模型和用户。
什么是 Function Calling ?原理是什么?
Function Calling 我的理解是这样一套机制:开发者用 JSON schema 把工具描述好传给模型,模型判断需要调工具的时候不输出自然语言,而是直接输出一段结构化的 tool_calls JSON,告诉你「我要调哪个函数、参数是什么」,你的代码拿到这段 JSON 去真正执行,把结果塞回对话,模型再生成最终答案。
整个流程本质上是两轮对话:第一轮模型说「我需要调这个工具」,你去执行,第二轮模型拿到执行结果说「答案是这个」。我觉得最核心的设计是,模型全程只做决策,执行的事情一律由宿主代码完成,职责分得很清楚。
Function Calling 解决了什么问题
LLM 在没有 Function Calling 之前,想让模型帮你调工具,完全靠解析自然语言。模型输出「我需要查一下北京的天气」,你再写 if/else 判断它「说」的是要查天气,然后手动去调 API。这个做法极其脆弱,模型换个说法,你的 if/else 就失配了,也根本没办法标准化。
Function Calling 的出现把这件事固定下来了:模型不再「说」要调工具,而是直接输出一段结构化的 JSON,开发者按格式解析就行,准确率大幅提升,也有了统一标准可以对接。这套机制由 OpenAI 在 2023 年推出,现在 Claude、Gemini、Qwen 等主流模型都支持。
MCP 和 Function Calling 有什么区别?有没有实际跑过 MCP?
我理解这两者不是竞争关系,解决的不是同一层面的问题。
Function Calling 是「调用语言」,定义的是模型怎么表达「我要调哪个函数、参数是什么」;
MCP 是「工具生态协议」,定义的是工具怎么标准化打包、注册和被 AI 客户端发现。MCP 底层其实还是用 Function Calling 来触发工具调用,只是在它之上加了一套工具管理框架,让工具实现一次、到处复用。
打个比方:Function Calling 像 HTTP 请求格式,MCP 像 REST API 的设计规范加服务注册发现机制,两者是不同层次的东西。
关于实际跑过的经验,我用 Claude Desktop 配过文件系统和 GitHub 的 MCP Server,在配置文件里加几行就能用,Claude 会自动发现工具,完全不用写对接代码。
你知道 MCP、Skill、Function Call 这三个的区别吗?
这三个概念其实分别处在不同的层次上。
Function Call是大模型调用外部工具的底层技术实现,让模型能够主动发起函数调用。
Skill可以理解为对一组相关Function的业务封装,比如"邮件处理技能"里可能包含发送、查询、删除等多个函数。
而MCP是模型上下文协议,它本质上是想建立一套标准化的通信规范,让不同的模型、工具和数据源之间能够更顺畅地互通互联。
简单来说,Function Call解决"怎么调",Skill解决"调什么",MCP解决"按什么规矩调"。
如果只是给单个应用接一两个工具、场景临时、不需要复用,Function Calling 就够了,简单直接,不需要引入额外的进程和配置。但只要工具需要跨项目或跨团队复用、或者数量多了管理麻烦、或者社区已经有现成的 MCP Server 可以直接配置,MCP 就值得上了。
判断的核心问题只有一个:这个工具会不会在这个应用之外被用到?会的话,把它封装成 MCP Server 是更长远的选择。此外,做 Agent 系统的话更应该选 MCP,工具来源多、数量大,手写 Function Calling 的维护成本会让代码变得难以管理。
A2A
A2A 协议有哪五大设计原则
A2A 是一种开放协议,为代理之间的协作提供了一种标准方式,与底层框架或供应商无关。协议遵循以下几个核心原则:
拥抱 Agentic 能力。A2A专注于使 agent 能多以自然、非结构化的方式进行协作,即使它们不共享内存、工具和上下文,我们正在实现真正的 multi-agent场景,而不会将 agent限制为“工具”。谷歌正在启用真正的多 agent场景,而不是限制 Agent 成为一个工具。
建立在现有标准之上。该协议建立在现有的流行标准之上,包括 HTTP、SSE、JSON-RPC,这意味着它更容易与企业日常使用的现有 IT 栈集成。
默认安全。A2A 旨在支持企业级身份验证和授权,在发布时与 OpenAPI的身份验证方案具有同等效力。
支持长时间运行的任务,我们设计了A2A,使其具有灵活性,并支持从快速任务到保度研究的各种场景,当人类处于循环中时,这些场最可能需要数小时甚至数天才能完成,在整个过程中,A2A可以向用户慢供实时反馈、通知和状态更新
模态无关。代理世界不仅限于文本,这就是为什么我们设计了 A2A 来支持各种模态,包括音频和视频流。
什么是 A2A 协议,它的核心架构及主要组件有哪些?
A2A(Agent-t0-Agent)协议是由 Goodle 主导开发的开放协议,旨在实现不同 AI 智能体之间的互操作性,使它们能够跨平台、跨框架地协作。其核心架构包括以下主要组件:
AgentCard(代理卡片):一个公开的JSON 文件,描述代理的能力、技能、端点 URL 和身份验证要求,用于客户端发现代理。
A2A Server(A2A 服务器):实现 A2A 协议方法的 HTTP 端点,接收请求并管理任务执行。
A2A Client(A2A 客户端):发送请求(如 tasks/send )到 A2A 服务器的应用程序或其他代理。
Task(任务):客户端发起的工作单元,具有唯一的ID,并通过状态(如 submitted、working)进行跟踪。
Message(消息):客户端与代理之间的通信回合,包含Parts。
Part(部分):消息或工件中的基本内容单元,可以是文本、文件或结构化 JSON。
Artifact(工件):代理在任务中生成的输出(如生成的文件、最终的结构化数据
Streaming(流式传输):对于长时间运行的任务,支持使用 tasks/sendsubscribe,客户端通过服务器发送事件(SSE)接收任务状态更新。
Push Notifications(推送通知):支持的服务器可以主动将仟务更新发送到客户端提供的 webhook URL
A2A 协议采用 JSON-RPC 2.0 通过 HTTP 进行消息交换,对于流式传输,使用 SSE 协议。
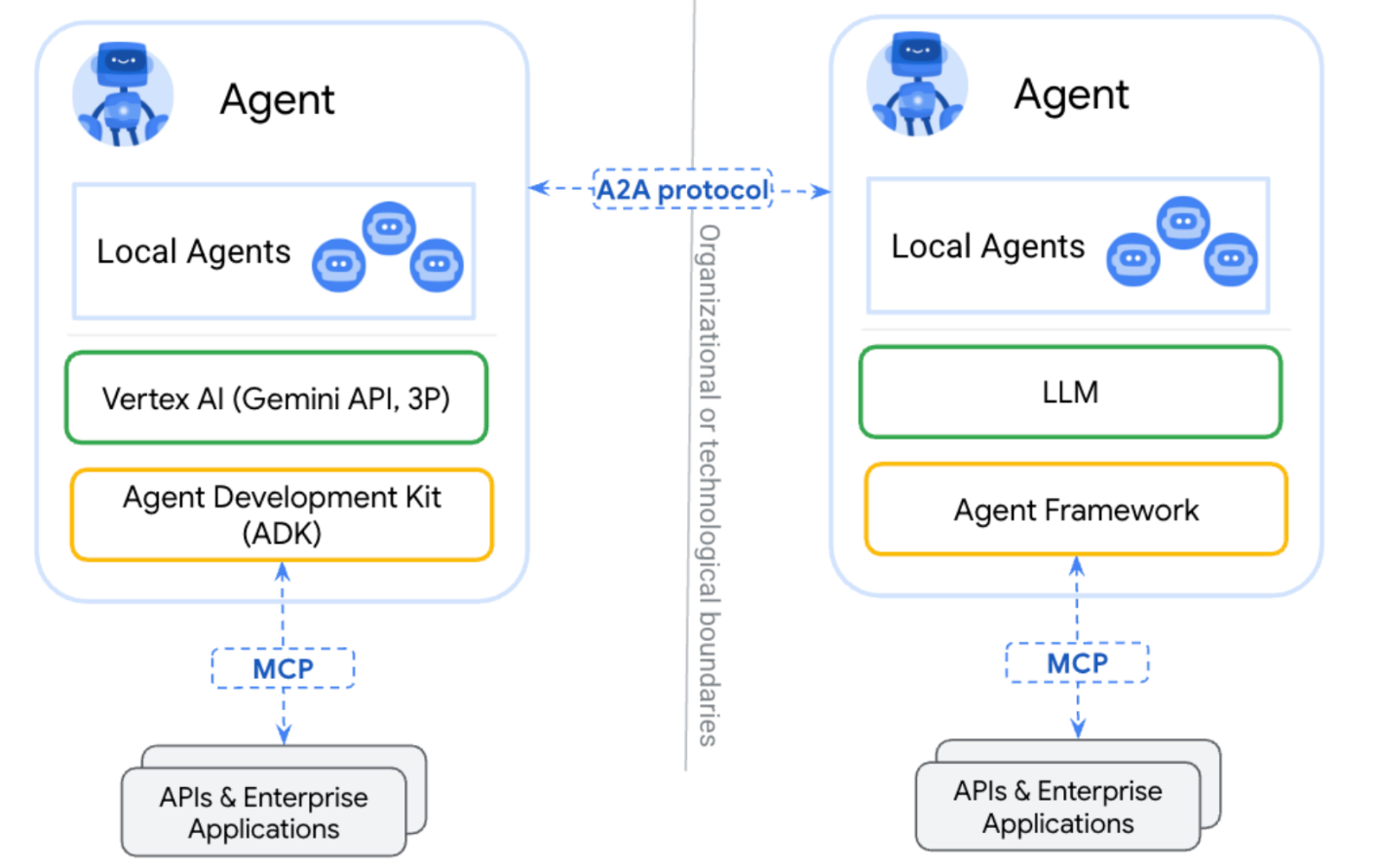
A2A 协议的工作原理是怎样的?
A2A协议的核心作用是让“客户端代理”和“远程代理”之间顺利沟通,客户端代理负责创建并下发任务,而远程代理则根据这些任务提供信息或执行操作,整个过程中,A2A 提供了几个关键功能。
能力发现:每个代理都有一张“Agent 卡”,以 JSON 格式描述它能做什么,客户端Agent可以通过这些卡片,找到最适合执行当前任务的远程Agent,并通过 A2A 协议与之建立通信。
任务管理:客户端与远程代理的交互围绕任务展开,每个任务都有一个由协议定义的“任务对象”,并且具有生命同期,有些任务可以立刻完成,而对于运行时间较长的任务,代理之间可以将续沟通,保持状态同步,确保任务按预期推进。任务完成后会产生一个“工件”,也就是最终的执行结果。
协作能力:代理之间可以直接通信,发送包含上下文、回复、工件或用户指令的消息,便于协同完成更复杂的任务。
用户体验协商:每条消息可以包含多个“部分”,每部分代表一个完整的内容片段,比如生成图像,每个部分都有明晚的内容类型,客户端和远程代理可以据此协商最合适的展示格式,同时也可以决定是否支持如iframe、视频、网页表单等用户界面功能,从而根据用户需求和设备能力,提供更好的使用体验。
A2A 协议的工作流程是怎样的?
发现:客户端向/.well-know/agent.json 发起HTP GET 请求,获取远端智能体的 AgentCard,其中包含智能体的唯一标识、能力清单、回调URL、认证方式等元数据,帮助客户端快速了解并筛选合适的智能体来执行任务
启动:客户端根据业务需求生成准一的Task ID,然后通过 JSON-RPC 调用tasks/send(用于一次性请求,同步返回最终 Task对象) 或 tasks/sendSubscribe (用于订阅式清求,服务端通过 Server-Sent Events 推送状态更新) 向目标智能体发送任务请求。
处理:远端智能体接收请求后,将任务状态从submitted 切换到 working,在内部执行模型推理或外部工具调用;对于订阅式任务,会持续性推送 TasksStatusUpdateEvent 和可选的 TaskArtifactUpdateEvent,让客户端实时获取讲度或中间成果。
交互:当智能体在处理过程中需要额外输入时,会发出 input-required 状态更新,并携带一条 Message 请求;客户端收到后可使用相同 TaskID 通过(tasks/send 或 tasks/sendSubscribe 补充用户输入。保持会话的连续性和上下文一致。
完成:任务进入终态(completed、failed或 canceled),客户端可以选择主动拉取最终的 Task对象,也可以继续通过SSE或 Webhook机制订阅 TaskStatusUpdateEvent,并获取以 JSON Artifact J形式封装的最终结果
A2A 协议 与 MCP 协议的关系是怎样的?
标准化协议:在智能体与外部系统之间实现互操作,标准化协议至关重要。它主要聚焦两个密切关联的领域:工具与智能体
工具是具有结构化输入输出、预定义行为的基本单元;
智能体则是能够调用工具、进行逻辑推理并与用户互动,从而完成新任务的自主应用。要真正满足用户需求,必须让智能体与工具协同工作,既发挥工具的专长,又利用智能体的灵活性
我理解它和 MCP 的区别是这样的:MCP 解决的是「单个 Agent 怎么连工具和数据」,A2A 解决的是「多个 Agent 之间怎么分工协作」。
一个 Agent 通过 A2A 可以把子任务委托给另一个专业 Agent,接收方按自己的 Skill 声明承接,支持异步长任务和流式推送结果。两者是互补的,不冲突:MCP 向下连工具,A2A 向上连 Agent,在复杂的多 Agent 系统里这两个通常都要用到。
下面具体介绍下:
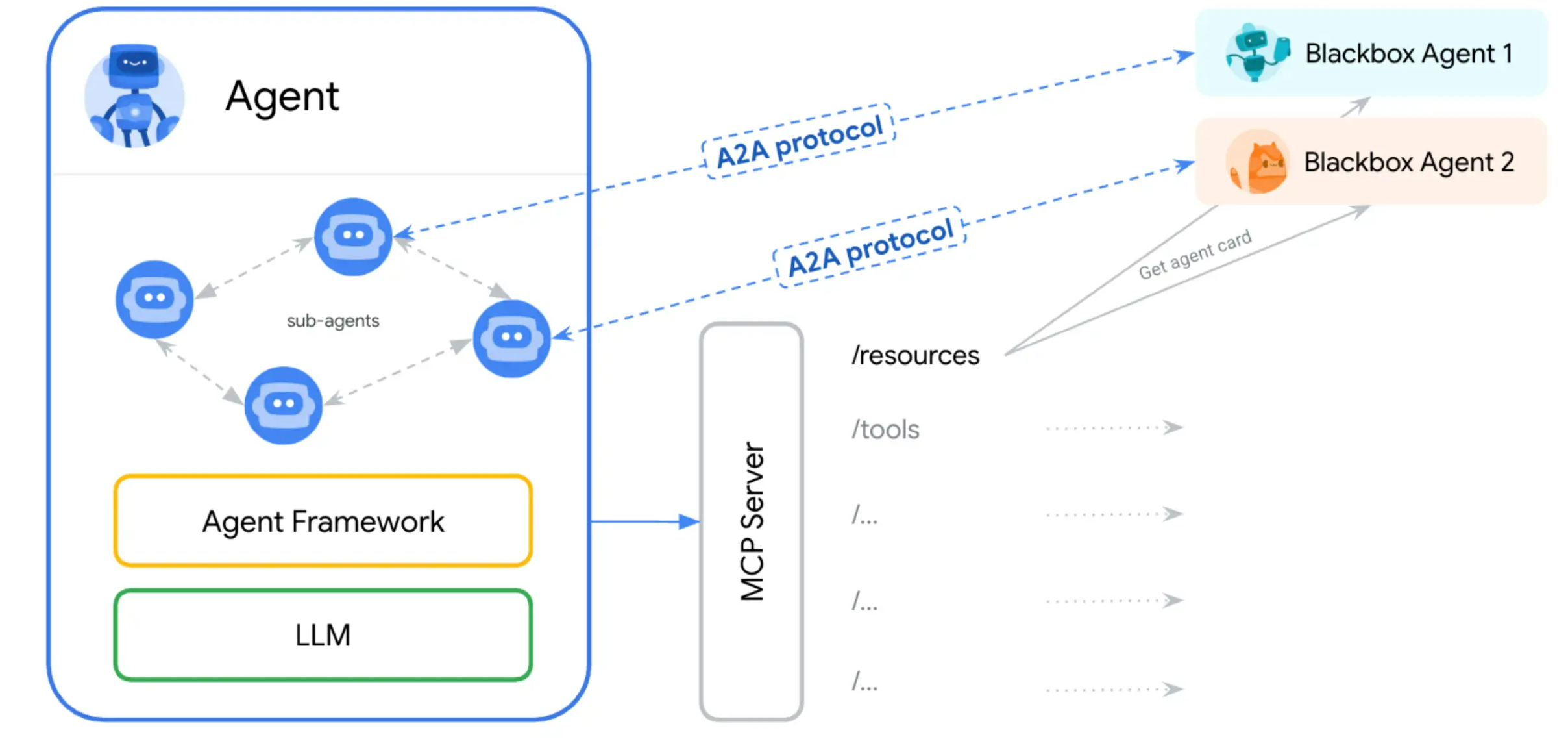 A2A 协议与 MCP 协议是两个在 AI 生态系统中扮演不同角色但又互补的标准协议。
A2A 协议与 MCP 协议是两个在 AI 生态系统中扮演不同角色但又互补的标准协议。
MCP (ModelContext protocoa):由 Anhropic 于2024年发布,旨在为 模型提供与外部数据源和工具的标准化连接方式。它允许模型通过统一的接口访问文件、数据库、API等资源,实现“函数调用”功能的标准化。MCP采用JSON-RPC2.0 协议,支持多种传输方式。如 STDIO和 HITP+SSE,它的核心在于提供一个“工具说明书”、让 AI模型能够安全,高效地与外部系统交豆
A2A Aent20:Aen) 协议:这是一个应用层物议,旨在实现 AI 智能体之间的自然语言协作,A2A允许不同的 AI 智能体之以" 智能体之”或“用户”的身份进行交流,而非仅仅作为工具被调用,它更关注 智能体之之间的沟通和协作,促进多智能体系统的协同工作。
两者的关系可以通过以下比喻来理解:
MCP 就像是一个“工具说明书”,告诉 AI 模型如何使用外部工具和数据。
A2A 就像是一个“电话簿”,让不同的 AI 智能体能够相互联系和协作。
因此,A2A 和 MCP 是互补的协议,共同推动了智能体生态的发展。
MCP
什么是 MCP 协议,它在 AI 大模型系统中的作用是什么?
MCP (Model Context Protocol,模型上下文协议)起源于2024年11月25 日 Anthropic 发布的文章:Introducing the Model context Protocol。旨在为大型语言模型(LLMs)和 AI助手提供一个统一、标准化的接口,使其能够无缝连接并交互各种外部数据源、工具等,让模型不依赖于预则练数据,还能在需要时动态获取最新的上下文信息、调用外部工具、执行特定任务。简单来说,它为 应用架构提供了一种“即插即用”的方式,类似于 USB-C让不同设备能够通过相同的接口连接一样。
MCP的目标是创建一个通用标准,使AI 应用程序的开发和集成变得更加简单和统一
可以将 MCP(模型上下文协议)比作AI 世界中的 USB-C接口。在传统的计算机环境中,只要外设(如盘标、键盘或U盘)符合 US8标准,系统便能只别并使用它们,同样地,MCP为大型语言模型 (LLM) 提供了一个统一的通信协议使得各种数据源和工具只需遵循 MCP的规范,便可与LLM无缝对接,这意味着,无论是数据库、API还是其他服务,只要通过 MCP 接入,LLM 都能理解并利用这些资源,从而扩展其功能和应用范围。
MCP 的作用主要体现在以下几个方面:
标准化数据接入:通过 MCP,我们无需为每个模型编写单独的代码,而是通过统一的协议接口,实现一次集成,随处连接。这大大简化了模型与外部系统的集成过程。
增强模型能力:MCP 使得模型能够实时访问最新的数据和工具,例如直接从 GitHub 获取代码库信息,或从 本地访问文件。这不仅提升了模型的实用性,也拓展了其应用场景。
提升系统可维护性:通过标准化的协议,系统的各个组件可以更加模块化地协作,降低了维护成本和出错概率。
MCP 为啥如此重要?
以前,如果想让AI处理我们的数据,基本只能靠预训练数据或者上传数据,既麻烦又低效。而且,就算是很强大的AI 模型,也会有数据隔离的问题,无法直接访问新数据,每次有新的数据进来,都要重新训练或上传,扩展起来化较困难
现在,MCP 解决了这个问题,它突破了模型对静态知识库的依赖,使其具备更强的动态交互能力,能够像人类一样调用搜索引擎、访问本地文件、连接 API 服务,甚至直接操作第三方库,所以 MCP相当于在 AI 和数据之间架起了一座桥。不管是获取最新的天气和新闻,还是进行数据分析、自动化办公,都能轻松搞定,更重要的是,只要大家都遵循MCP这套协议,AI 就能无缝连接本地教据、互联网资源、开发工具、生产力软件,甚至整个社区生态,实现真正的 “万物互联”,这将极大提升 Al的协作和工作能力,价值不可估量。
MCP 架构包含哪些核心组件?
MCP 的核心是客户端-服务器架构,其中主机应用程序可以连接到多个服务器
MCP 主机:希望通过 MCP 访问数据的程序,例如 Claude Desktop、IDE 或 AI 工具。
MCP 客户端:与服务器保持 1:1连接的协议客户端
MCP 服务器:轻量级程序,通过标准化的 MCP 协议向客户端提供特定功能,如数据源、工具和API接口等
本地数据源:MCP 服务器可以安全访问用户的计算机文件、数据库和服务。
远程服务:MCP 服务器可通过互联网(例如通过 API)连接到的外部系统。
MCP 协议支持哪两种模式?
MCP 协议支持两种主要的通信模式,即标准输入输出(Stdio)模式和 服务器发送事件(SSE)模式:
标准输入输出(Stdio)模式:基于 Stdio 的实现是最常见的 MCP客户端方案,它通过标准输入输出流与 MCP 服务器进行通信,这种方式简单直观,能够直接通过进程自通信实现数据交互,避免了额外的网络通信开销,特别适用于本地部署的MCP服务器,可以在同一台机器上启动 MCP 服务器进程,与客户端无缝对接。
服务器发送事件(SSE)模式:这个方案相较于Stdio 方式,SSEE 更适用于远程部署的MCP服务器,比如分布式系统或需要网络实对推送的场景。客户端可以通过标准HTTP 协议与服务器建立连接,实现单向的实时数据推送送。基于 SSE的 MCP服务器支持被多个客产端的远程调用。
MCP 与 Function Calling 的区别是什么?
MCP是一个抽象层面的协议标准,它规定了上下文与请求的结构化传递方式,并要求通信格式符合JSON-RPC2.0 标准,它提供了标准化的通信机制,确保不同模型之间的兼容性,我们只需按照协议开发一次接口,即可被多个模型调用,避免了为每个模型单独适配的繁琐工作。
Function calling则是某些大模型(如 OenpenAI的GPT-4)提供的特有接口特性,它以特定的格式让 LLM 能产出一个函数调用清求,然后应用可以读取这个结构化的请求去执行对应的操作并返回结果。但这个特性本身并不要求消息一定是JSON-RPC格式,也不一定遵守 MCP的上下文管理方式。它是由大模型服务提供商定义的一种调用机制,与MCP 所定义的协议与标准没有内在依赖或直接关联。
其实MCP和Function calling两者是完全不同层面的东西,MCP是一个更底层、更通用的抽象标准,相当于一个基础设施。而 Function calling 则是大模型一个特定的服务,更偏向于具体实现,以支付系统来举例子,以前的 Function calling 相当于请求各个支付系统,微信,支付宝,银联,每个系统都需要单独对接,而 MCP相当于支付网关,只需要对接支付网关,后面对接各种支付系统都是支付网关做,我们不用管。因此 MCP协议通过统一 通信规范和资源定义标准,实现了“一次开发,全平台通用”的目标。借助 MCP,我们只需按照协议开发一次接口,便可无缝适配 ChatGPT、DeepseeK等不同模型,显著降低了集成成本和复杂性。
Tools 注册与调用遵循什么标准格式?
在工程落地中,Tool 的定义与接入经历了一个从“各自为战”到“双层标准化”的演进过程。要让 Agent 准确理解并调用外部工具,业界目前依赖两大核心标准协议:底层数据格式标准(OpenAI Schema) 与 应用通信接入标准(MCP)。
数据格式层:OpenAI Function Calling Schema
不论外部工具多么复杂,LLM 在推理时只认特定的数据结构。当前业界处理工具描述的数据格式标准高度统一于 OpenAI Function Calling Schema,Anthropic(Claude)、Google(Gemini)等主要模型提供商均已对齐这套规范或提供高度兼容的实现。
核心机制:通过 JSON Schema 严格定义工具的描述和参数规范。LLM 在推理时只消费这部分 JSON Schema 来理解工具的功能边界,从而决定"是否调用"以及"如何填充参数"。
标准 JSON Schema 结构示例(以查询服务慢 SQL 日志为例):
工具描述的质量直接决定 Agent 的决策准确性。 模型是否调用工具、调用哪个工具、如何填充参数,完全依赖对 description 字段的语义理解。好的工具描述应明确说明"何时该调用"和"何时不该调用",参数的 description 应包含格式要求和典型示例值。
进阶封装:Skills 的双重形态
当多个原子工具需要在特定场景下被反复组合调用时,可以将这一调用序列封装为一个 Skill(技能),对外暴露为单一的可调用接口。
Skills 不是独立于 Tools 之外的新能力层,而是 Tools 在工程实践中的高阶封装形态。它解决的是"多步工具组合的复用与标准化"问题,其注册和调用方式与原子 Tools 完全一致,LLM 的视角中两者没有本质区别。
在实际的工程落地中,由于应用场景的不同,Skill 发展出了两种截然不同的形态:
作为复合工具(常见于后端 Agent 框架如 Spring AI、LangChain):即上述提到的,将多个原子工具在代码层封装为高阶工具,对外暴露单一的 JSON Schema。它对 LLM 是黑盒的,核心价值是降低推理步骤和 Token 消耗。
作为任务说明书 / SOP(常见于 AI 编程生态如 Cursor、Claude Code):Skill 是一个用自然语言定义的逻辑指令集(如 Markdown 文档)。它通过延迟加载的方式,将特定领域的规则、流程和团队约束(如代码规范、Code Review 标准)动态注入到 LLM 的上下文中。它对 LLM 是白盒的,核心价值是将老员工脑子里的“隐性知识”显性化,指导 Agent 处理极度灵活的复杂任务。
通信接入层:MCP (Model Context Protocol)
如果说 Function Calling Schema 解决了"模型如何听懂工具请求“的问题,那么 Anthropic 于 2024 年 11 月推出的 MCP 则解决了”工具如何标准化接入宿主程序“的问题。
在过去,开发者必须在代码层手动维护大量定制化的字典映射(即 "工具名称" → { 实际执行函数, JSON Schema 描述 }),导致生态极度碎片化——每接入一个新工具都需要手写胶水代码。MCP 提供了一套基于 JSON-RPC 2.0 的统一网络通信协议(被誉为 AI 领域的"USB-C 接口”)。通过 MCP Server,外部系统(如本地文件、数据库、企业 API)可以标准化地向外暴露自身能力;宿主程序(Host)只需连接该 Server,就能自动发现并注册所有工具,彻底解耦了 AI 应用与底层外部代码。
MCP Server 在向外暴露工具时,内部依然使用 JSON Schema 来描述每个工具的参数规范。也就是说,JSON Schema 是底层的数据格式基础,MCP 是在其之上构建的通信协议层。
此外,MCP 并非只管工具接入,它实际上定义了三类标准原语: 原语类型作用典型示例Tools可执行的函数,供 LLM 主动调用查询数据库、发送邮件、执行代码Resources只读数据资源,供 Agent 按需读取本地文件、数据库记录、实时日志流Prompts可复用的提示词模板标准化的代码审查模板、故障报告模板
MCP 的工作流程是什么?
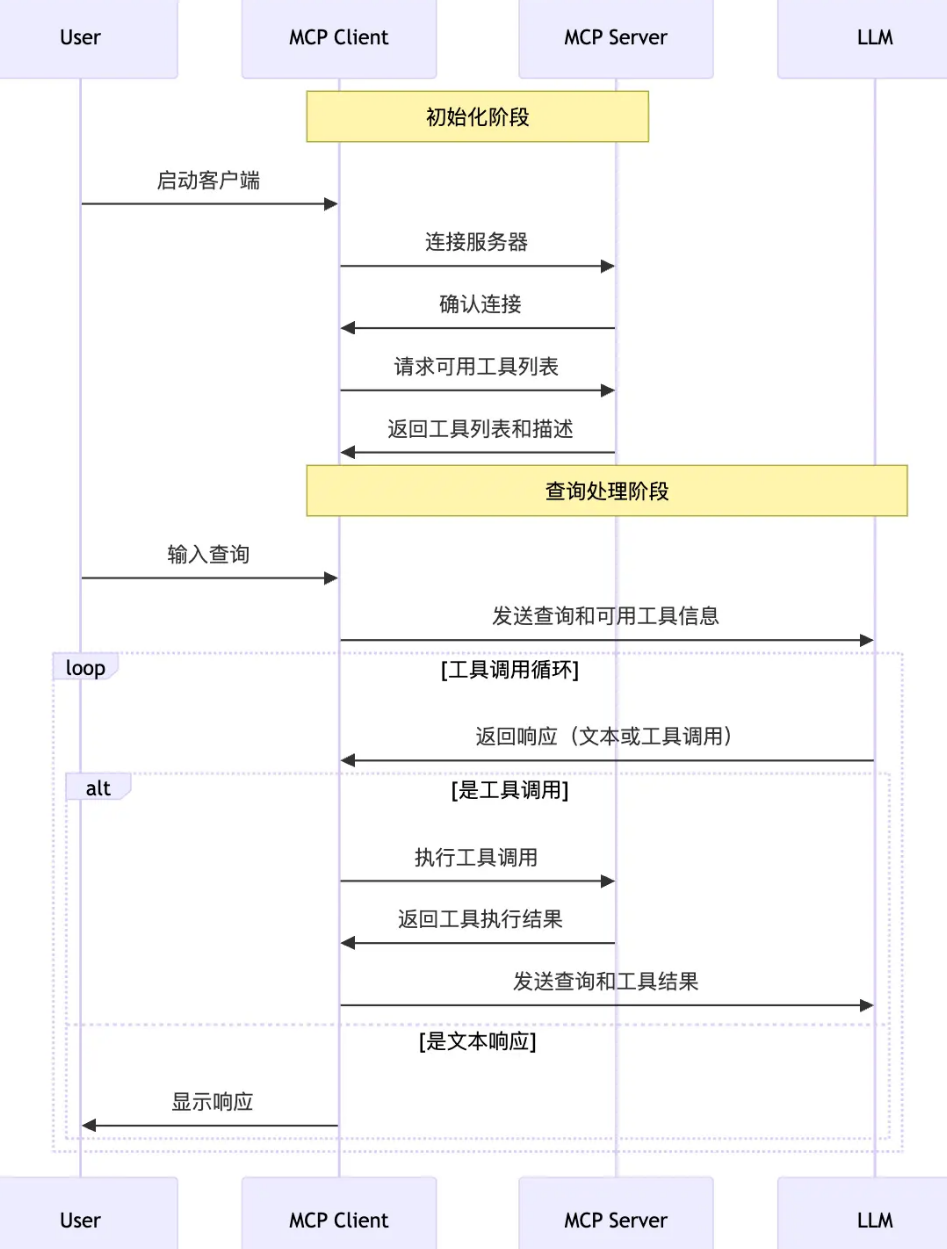
初始化连接:主机应用程序(如 Claude Desktop 或 IDE 插件)启动并初始化 MCP 客户端,每个客户端与一个 MCP 服务器建立连接
获取工具列表:在系统初始化阶段,MCP ient 首先从 MCPserver获取可用的工具清单和能力描述,这些工具可以是 API、脚本、数据库查询方法等。这个步骤相当于“能力注册”,让模型知道有哪些可以用的““外部技能”
构造 Function Calling 请求:当用户输入一个问题后,MCP Cient会将这些工具描述(包括参数、用途、返回值等)一并传给 LLM,传输方式采用Function Calling,即结构化地把“能用的函数长什么样”告诉模型,让它来决定是否要使用。
模型智能判断是否调用工具:LLM 根据当前对话上下文以及工具信息判新是否要使用某个工具,并决定调用哪一个、传入什么参数。这个阶段完全由模型推理完成,比如它可以判断“这题需要查天气,那我就调用 getWeather工具”
工具调用执行阶段:如果模型发起调用请求,MCP Cient 会根据模型的选择,通过 MCPServer发起工具调用。这一步是真正的“执行动作”。MCP Server 去实际跑工具的逻辑,并把结果返回给客户端,
结果返回与模型整合:工具执行结果(比如调用 API得到的数据)被传回 LLM,由模型将这个结果与原始用户问题、已有上下文等信息整合,生成最终的自然语言回应。
用户响应输出:最后,MCP Client 将模型生成的回答展示给用户,完成一次完整的“智能+工具”协作流程。
MCP 协议安全性设计包含哪些层面?
MCP协议的安全性设计涵盖多个关键方面,旨在确保大模型系统在与外部和资源交互时的安全性和可靠性,MCP的安全性设计主要包括以下几个方面:
用户同意和控制:所有模型对工具、资源和是示的访问请求都必须经过用户的授权,主机负责管理权限、提示用户批准,并在必要时阻止未经授权的访问,用户必须知道哪些数据是需要提供给大模型的,用户在授权使用之前了解每个工具的功能
隔离与沙箱机制:MCP的设计将实际工具调用封装在MCP Server内部,模型本身无法直接访问敏感数据、这种“中间层”设计有效地降低了直接暴露内部业务系统的风险。同时,沙箱加制可以限制工具调用的执行环境,防止任意代码执行或恶意操作对系统造成破坏。
加密传输与来源验证:MCP 内置了安全机制,确保只有经过验证的请求才能访问特定资源,相当于在数据安全又加上了一道防线,同时,MCP协议还支持多种加密算法,以确保数据在传输过程中的安全性。
如何将已有的应用转换成 MCP 服务?
要将现有应用转换为 MCP服务,需将其功能封装为标准化的 MCP工具(Tools)、资源(Resources)或提示(Prompts),并通过MCP Senver 对外暴露,这一过程涉及以下关键步骤:
梳理功能模块:识别应用中要提供给外部调用的功能,如 API 接口、数据查询、文件处理等
创建单独的MCP 服务:创建一个新的MCP 服务,与已有的业务服务隔离开,通过单独的 API或者 SDK 和业务服务通信。
定义工具:定义 MCP 服务需要包含的工具功能描述、方法入参字段和描述、方法返回的字段和描述。
实现 MCP Server:根据 MCP 协议规范,构建一个 MCP Server,负责接收 MCP 客户端请求、调用相应功能模块,并返回结果。